








In this tutorial, we'll see how to solve a common Pandas read_csv() error – Error Tokenizing Data. The full error is something like:
ParserError: Error tokenizing data. C error: Expected 2 fields in line 4, saw 4
The Pandas parser error when reading csv is very common but difficult to investigate and solve for big CSV files.
There could be many different reasons for this error:
- "wrong" data in the file
- different number of columns
- mixed data
- several data files stored as a single file
- nested separators
- wrong parsing parameters for read_csv()
- different separator
- line terminators
- wrong parsing engine
Let's cover the steps to diagnose and solve this error
1: Reason for pandas.parser.CParserError: Error tokenizing
Suppose we have CSV file like:
col_1,col_2,col_3
11,12,13
21,22,23
31,32,33,44
which we are going to read by - read_csv() method:
import pandas as pd
pd.read_csv('test.csv')
We will get an error:
ParserError: Error tokenizing data. C error: Expected 3 fields in line 4, saw 4
We can easily see where the problem is. But what should be the solution in this case? Remove the 44 or add a new column? It depends on the context of this data.
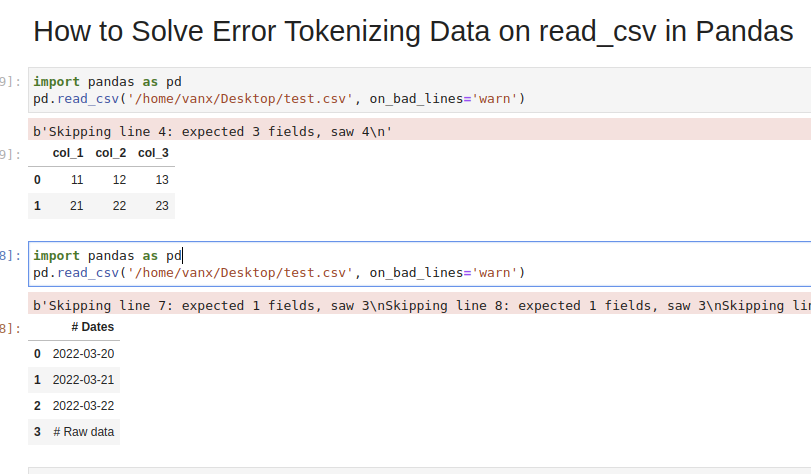
If we don't need the bad data we can use parameter - on_bad_lines='skip' in order to skip bad lines:
pd.read_csv('test.csv', on_bad_lines='skip')
For older Pandas versions you may need to use: error_bad_lines=False which will be deprecated in future.
Using warn instead of skip will produce:
pd.read_csv('test.csv', on_bad_lines='warn')
warning like:
b'Skipping line 4: expected 3 fields, saw 4\n'
To find more about how to drop bad lines with read_csv() read the linked article.
2: How To Fix pandas.parser.CParserError: Error tokenizing
In some cases the reason could be the separator used to read the CSV file. In this case we can open the file and check its content.
If you don't know how to read huge files in Windows or Linux - then check the article.
Depending on your OS and CSV file you may need to use different parameters like:
sep-lineterminator-engine
More information on the parameters can be found in Pandas doc for read_csv()
If the CSV file has tab as a separator and different line endings we can use:
import pandas as pd
pd.read_csv('test.csv', sep='\t', lineterminator='\r\n')
Note that delimiter is an alias for sep.
3: Use different engine for read_csv()
The default C engine cannot automatically detect the separator, but the python parsing engine can.
There are 3 engines in the latest version of Pandas:
cpythonpyarrow
Python engine is the slowest one but the most feature-complete.
Using python as engine can help detecting the correct delimiter and solve the Error Tokenizing Data:
pd.read_csv('test.csv', engine='python')
4: Identify the headers to solve Error Tokenizing Data
Sometimes Error Tokenizing Data problem may be related to the headers.
For example multiline headers or additional data can produce the error. In this case we can skip the first or last few lines by:
pd.read_csv('test.csv', skiprows=1, engine='python')
or skipping the last lines:
pd.read_csv('test.csv', skipfooter=1, engine='python')
Note that we need to use python as the read_csv() engine for parameter - skipfooter.
In some cases header=None can help in order to solve the error:
pd.read_csv('test.csv', header=None)
5: Autodetect skiprows for read_csv()
Suppose we had CSV file like:
Dates
2022-03-20
2022-03-21
2022-03-22
Raw data
col_1,col_2,col_3
11,12,13
21,22,23
31,32,33
We are interested in reading the data stored after the line "Raw data". If this line is changing for different files and we need to autodetect the line.
To search for a line containing some match in Pandas we can use a separator which is not present in the file "@@".
In case of multiple occurrences we can get the biggest index. To autodetect skiprows parameter in Pandas read_csv() use:
df_temp = pd.read_csv('test.csv', sep='@@', engine='python', names=['col'])
ix_last_start = df_temp[df_temp['col'].str.contains('# Raw data')].index.max()
result is:
4
Finding the starting line can be done by visually inspecting the file in the text editor.
Then we can simply read the file by:
df_analytics = pd.read_csv(file, skiprows=ix_last_start)
6: Update CSV file to align headers and values
As we mentioned the most common reason for this error is the different number of values in comparison to columns. The example CSV file will raise the error:
col_1,col_2,col_3
1,2,3
4,5,6
7,8,9,0
Easy fix for ParserError: Error tokenizing data. C error: Expected 3 fields in line 4, saw 4 is to change the headers of the CSV file to the number shown in the error.
So you can simply change the file to:
col_1,col_2,col_3,col_4
1,2,3
4,5,6
7,8,9,0
This will fix the Pandas error - ParserError: Error tokenizing data
Conclusion
In this post we saw how to investigate the error:
ParserError: Error tokenizing data. C error: Expected 3 fields in line 4, saw 4
We covered different reasons and solutions in order to read any CSV file with Pandas.
Some solutions will warn and skip problematic lines. Others will try to resolve the problem automatically.