








This is a Python/Pandas vs R cheatsheet for a quick reference for switching between both. The post contains equivalent operations between Pandas and R. The post includes the most used operations needed on a daily baisis for data analysis.
Have in mind that some examples might differ due to different indexing or updates.
If you want to contribute feel free to suggest changes or additions on GitHub: pandas_r_cheatsheet.csv
Pandas vs R cheatsheet
Setup

import pandas as pd
import numpy as nppip install pandashttps://pypi.org/Data Structures

s = pd.Series(np.arange(5))s[0]df = pd.DataFrame(
{'col_1': [11, 12, 13],
'col_2': [21, 22, 23]},
index=[0, 1, 3])import numpy as np
import pandas as pd
data = np.random.randn(10, 3)
cols = list('abc')
pd.DataFrame(data, columns=cols)Read

df = pd.read_csv('file.csv')pd.read_json('file.json')pd.read_csv('https://example.com/file.csv')df = pd.read_fwf('delim_file.txt')Write

df.to_csv('file.csv')df.to_json('file.json')Inspect Data

df.shapedf.head(6)df.tail(6)df.describe()df.loc[:, :'a'].describe()df['A'].mean()
df.sample(n=10)Select
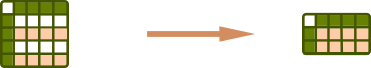
df.loc[1:3, :]df.loc[[1, 2, 3], :]df.loc[:, ['a', 'b']].copy()df.loc[:, ['a']]df.loc[1:3, ['b', 'a']]df.loc[[3,1], ['b', 'a']]df[df['a'].isna()]df['a'].dropna()Add rows/columns
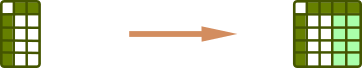
df['new col'] = df['col'] * 100df['new col'] = Falsedf.loc[-1] = [1, 2, 3]df.append(df2, ignore_index = True)Drop rows/columns/nan
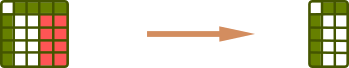
s.drop(1)s.drop([1, 2])df.drop('b' , axis=1) df.dropna()df.dropna(axis=1)Sort values/index
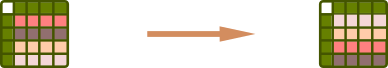
sorted([2,3,1])sorted([2,3,1], reverse=True)df['a'].sort_values()df.sort_values(['a', 'b'], ascending=[False, True])Filter

df.loc[:, df.isna().any()]df.loc[df.isna().any(), :]df[df['col_1'] > 100]df[(df['a']=='a')&(df['b']>=10)]df[df['a'] == 'test']df[(df['a'] == 'test') & (df['b'] == 'a2') ]Group by
df.groupby('a')df.groupby(['a', 'b']).c.sum()df['a'].value_counts()Convert

df['a'].fillna(0)df.replace('..', None)df['col_1'].astype('int64')pd.to_datetime(df['date'], format='%Y-%m-%d')P.S. Due to bug in the blog platform <- is displayed with R comment. So instead of: s <- 0:4 the code is shown as s <- 0:4 #>
0. How to Install R Packages
To install new packages in R follow these steps:
- Launch your R console or RStudio.
- Install single package
install.packages('jsonlite')
- To install multiple packages simultaneously:
install.packages(c('jsonlite', 'ggplot2'))
- R will download and install the specified packages from the CRAN (Comprehensive R Archive Network) repository.
Once the installation is complete, you can load the package into your R session using the library('jsonlite') function.
Install ggplot2 in R
For example, to install the "ggplot2" package, you can use the commands:
install.packages('jsonlite')
library('jsonlite')
1. Main Differences: R and Pandas
Pandas and R are both popular tools/languages for data analysis, manipulation and statistics. Some key differences between them:
Indexing
One big difference between R and Pandas is indexing:
- R - 1 based
* Indexing from zero in R
* Package ‘index0’
* Pandas - 0 based
Syntax
- R syntax is tailored for statistical analysis. It uses functions and operators that are well-suited for data manipulation, statistics and visualization.
- Pandas uses Python syntax, which is more general-purpose. It leverages Python's data structures like DataFrames and Series for data manipulation. Pandas also use the indexing, slicing and other Python techniques.
Below you can compare the creation of DataFrames in Pandas vs R:
# pandas
import pandas as pd
df = pd.DataFrame(np.random.randn(10, 5), columns=list("abcd"))
df[["a", "c", "d"]]
vs
# R
df <- data.frame(a=rnorm(10), b=rnorm(10), c=rnorm(10), d=rnorm(10))
df[, c("a", "c", "d")]
Data Structures
- R - uses data structures like:
- Vectors
- Lists
- Matrices
- Dataframes
- Pandas - Intro to data structures
- DataFrames
- Series
DataFrames are the primary data structure for data analysis in R and Pandas.
Performance
R is considered to be faster for most operations in comparison to Pandas. For smaller datasets Pandas might be close to R.
To test performance we can use dataset with 2GB/10M rows - Game Recommendations on Steam:
# pandas
%%time
import pandas as pd
df = pd.read_csv('recommendations.csv')
df['hours'].mean()
# R
library(microbenchmark)
microbenchmark(df <- read.csv('recommendations.csv'), mean(df[, 'hours']))
end
The results are:
- Pandas
CPU times: user 17.1 s, sys: 4.38 s, total: 21.5 s
Wall time: 23.7 s
103.97299330788391
- R timing
| expr | min | lq | mean | median | uq | max neval | |
|---|---|---|---|---|---|---|---|
| df <- read.csv | 141 | 141 | 142 | 141 | 142 | 143 | 10 |
| mean(df[, "hours"]) | 0.11 | 0.11 | 0.11 | 0.11 | 0.11 | 0.11 | 10 |
As we can see times are close for R and Pandas for this use case.
Package Ecosystem
Both offer mature package systems with a wide variety of packages related to data analysis and visualization.
- R has a vast repository of packages on CRAN (Comprehensive R Archive Network) dedicated to statistics, data analysis, and visualization.
- Pandas is part of the Python ecosystem, which has a broader range of packages for various purposes beyond data analysis.
Community
-
R has a strong community of experienced statisticians and data analysts, and there are numerous resources and documentation available for R users.
-
Pandas benefits from the larger Python community, which offers extensive resources and documentation for data analysis and programming in general. People from different scientific areas join Python and Pandas communities to solve everyday problems.
Learning Curve
Again it depends on personal choice. Python is considered as one of the best programming languages for beginners. R is far below Python in recent surveys for loved language:
stackoverflow survey - Most loved, dreaded, and wanted
3. Pandas vs R - useful links
| Pandas | R | |
|---|---|---|
| data analysis tool | language for statistical computing | |
| site | https://pandas.pydata.org/ | https://www.r-project.org/ |
| docs | https://pandas.pydata.org/docs/ | https://cran.r-project.org/manuals.html |
| packages | https://pypi.org/ | https://cran.r-project.org/web/packages/ |
| repo | https://github.com/pandas-dev/pandas | - |
| cheatsheet | Data Wrangling with pandas | Data Wrangling with dplyr and tidyr |
| basics | https://pandas.pydata.org/docs/user_guide/basics.html | https://cran.r-project.org/doc/manuals/r-release/R-intro.pdf |
| getting started | https://pandas.pydata.org/docs/getting_started/index.html | https://education.rstudio.com/learn/beginner/ |
| indexing | 0 based | 1 based |
| missing value | np.nan | NA |
| Boolean | False/True | FALSE/TRUE |
| Comments | # comment | # comment |
4. Summary & Resources
In summary, Pandas and R are both powerful tools for data analysis, visualization and manipulation.
Ultimately, the choice between R and Pandas often depends on your specific needs, existing familiarity with a programming language, and the ecosystem of packages that best suit your data analysis tasks.
Personally I find Pandas easier to learn and start because of the previous experience in Python language. Knowing Pandas or R makes it easier to transition to the other one.
- Comparison with R / R libraries
- Pandas Cheat Sheet for Data Science
- Pandas vs SQL Cheat Sheet
- Pandas vs Julia - cheat sheet and comparison
- pandas notebook
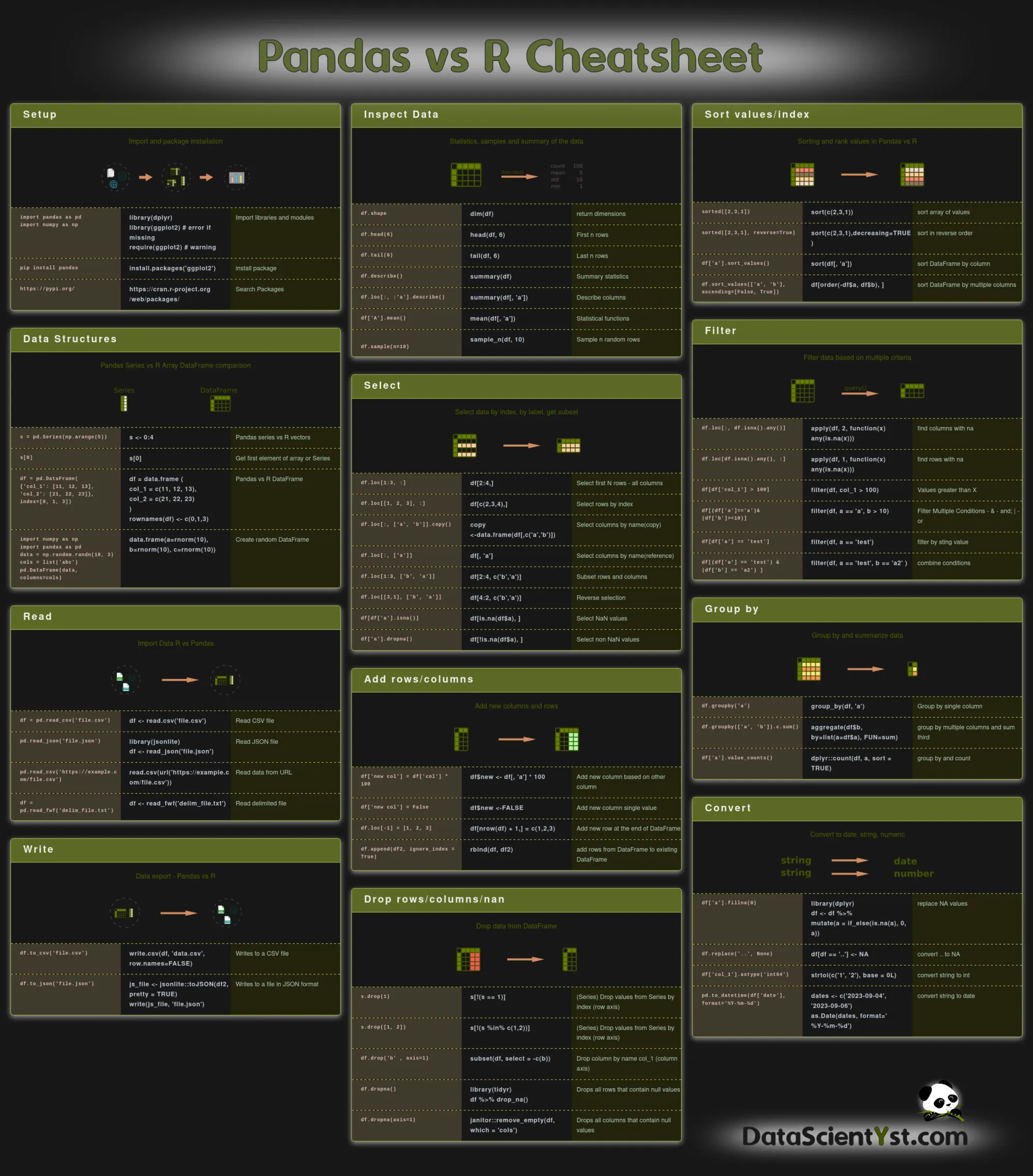
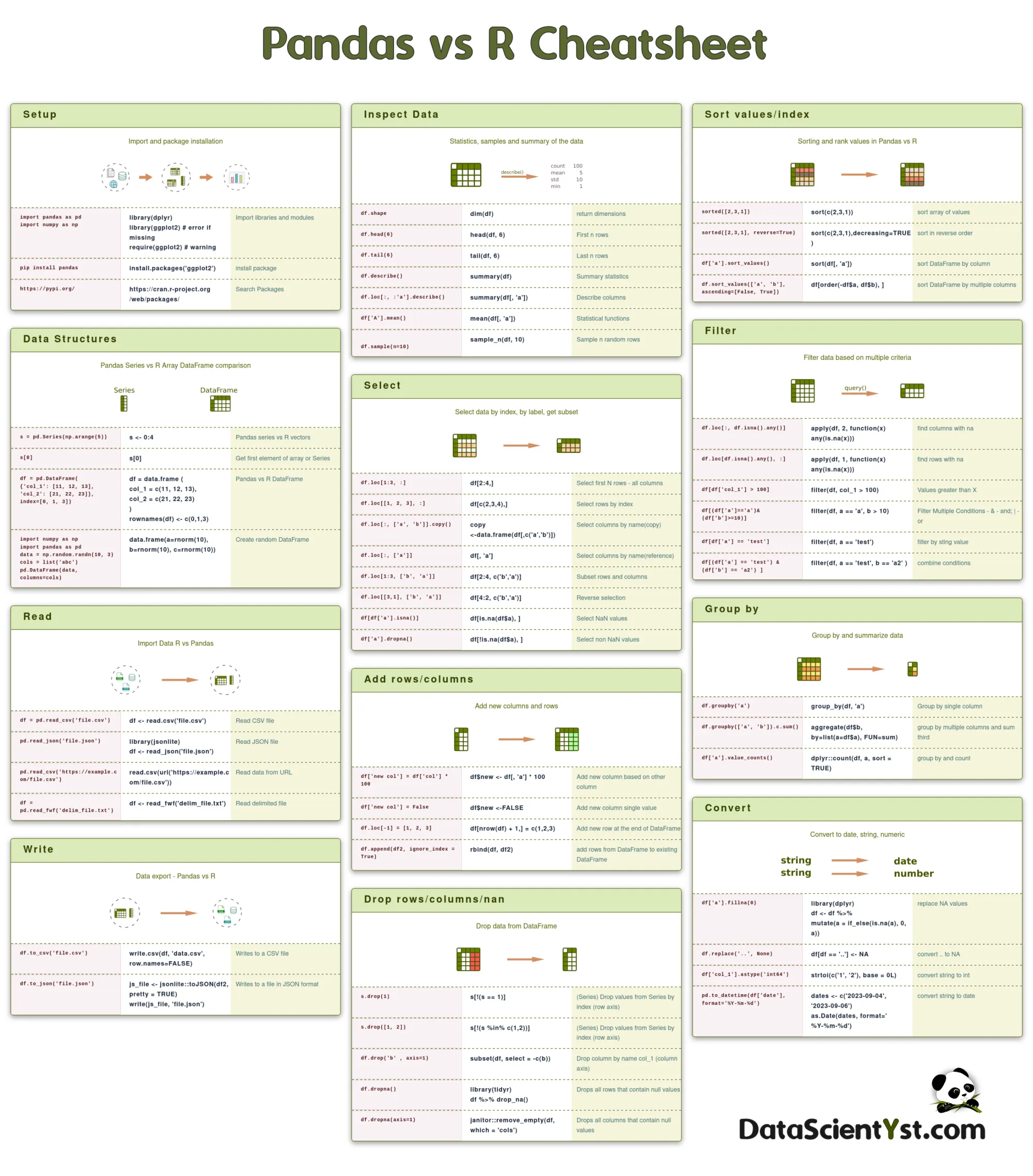
5. Pandas vs R Cheat Sheet Image
Dark version:
Light Version:
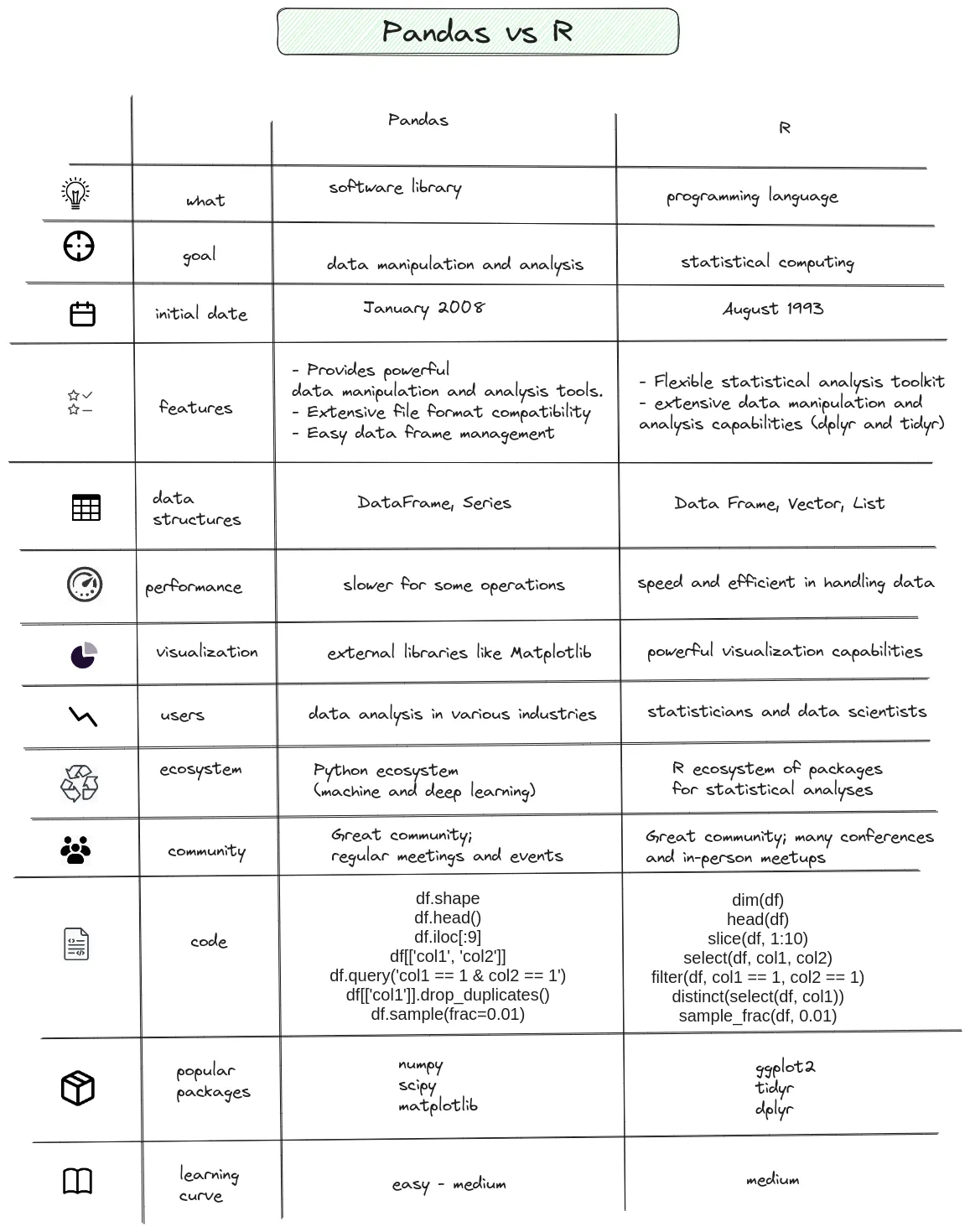
6. Pandas vs R comparison
We are working on a visual comparison between R and Pandas. Below you can find a quick teaser:
P.S. We were overloaded in the last year so we were not able to post frequently. We hope to have more time for this project and data science.