








Cheat sheet for working with datetime, dates and time in Pandas and Python. The cheat sheet try to show most popular operations in a short form. There is also a visual representation of the cheat sheet.
Pandas is a powerful library for working with datetime data in Python. Pandas offer variaty of attributes, methods, classes to work with date and time. The picture below illustrates most of them:
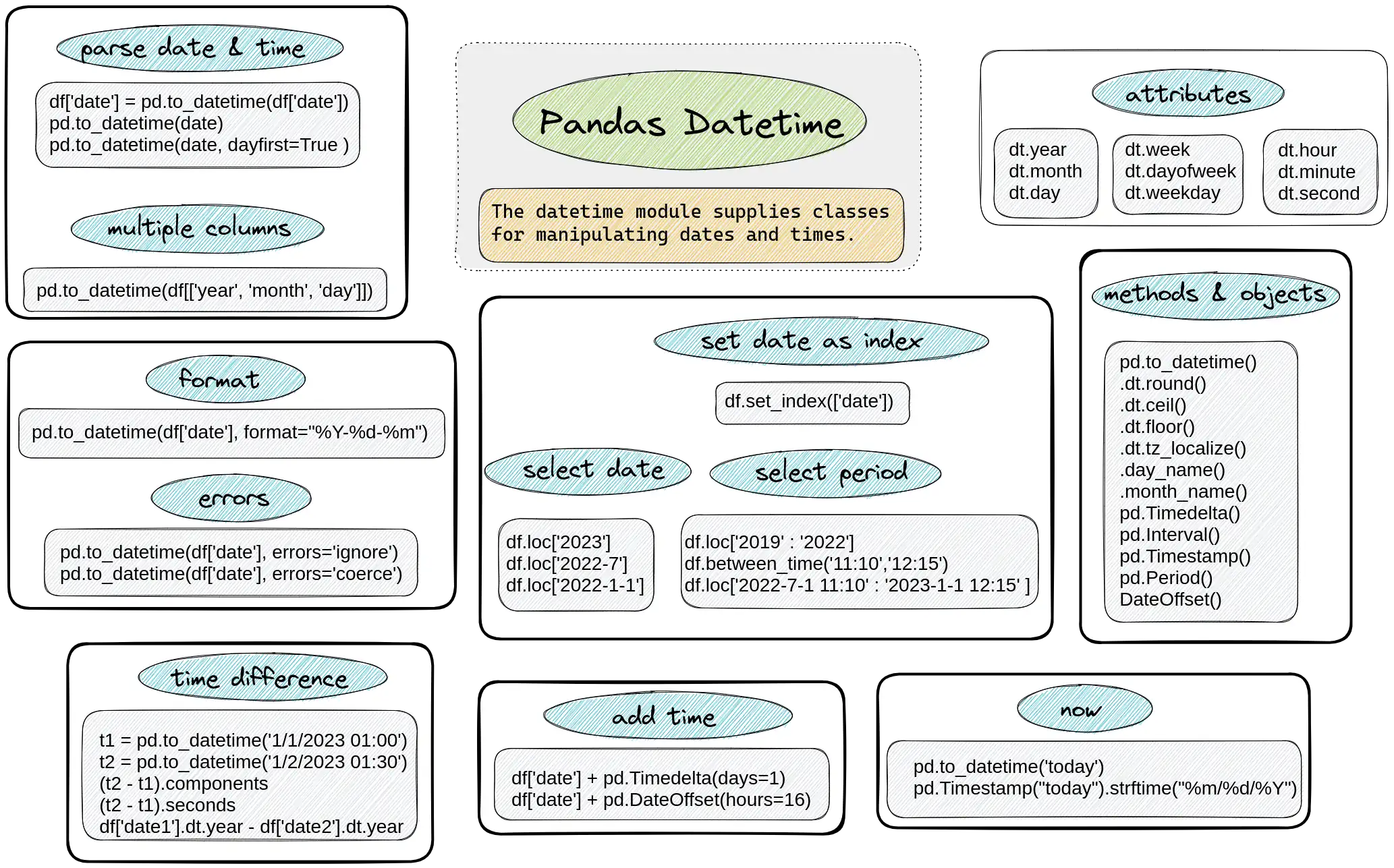
The idea of this post is to save your time and effort of googling the same commands over and over. If you have an idea how to improve it - please let us know! Thank you!
Pandas Datetime Cheat Sheet
import
datetime related libraries
from datetime import datetime, timedeltamanipulating dates and times
import pandas as pdworking with datetime Series
impot timevarious time-related functions
now & today
pd.to_datetime('today')get current date and time in local timezone
pd.to_datetime('now')current timestamp in UTC
pd.to_datetime('today').normalize()today's date midnight
datetime.today().strftime('%d/%m/%Y')get current date in a given format
time.strftime('%d/%m/%Y')use module time for current date & time
datetime.datetime.now().isoformat()get local timestamp ISO format
datetime.datetime.utcnow().isoformat()get UTC time in ISO format
parse date & time
pd.to_datetime('2023-01-11 16:11:26.862697')parse sting to datetime
pd.to_datetime(df['date'])parse column to datetime
pd.to_datetime(df['date'], dayfirst=True)specify parse order - True 10/11/12 is parsed as 2012-11-10
pd.to_datetime(df['date'], yearfirst=True)True - 10/11/12 is parsed as 2010-11-12
pd.to_datetime(df['date'], infer_datetime_format=True)infer the date format based on the first non-NaN item
pd.to_datetime(df['date'], format='%Y-%m-%d %H:%M:%S')specify parsing format %Y-%m-%d %H:%M:%S
pd.to_datetime(df[['year', 'month', 'day']])parse multiple columns
attributes
dt.yearget year from datetime
dt.monthget month from datetime
dt.dayget day from datetime
dt.hourget hour from datetime
dt.minuteget minute from datetime
dt.secondget second from datetime
dt.day_of_yearget day of the year from datetime
dt.dayofweekreturn the day of the week
dt.is_leap_yearboolean indicator if the date belongs to a leap year
dt.daysinmonththe number of days in the month
dt.daysinmonththe number of days in the month
methods
popular datetime methods
dto = pd.to_datetime('2023-01-11 16:11:26.862697')
dto.day_name()return the day names with specified locale
dto.month_name()return the month names with specified locale
dto.tz_localize('UTC')localize tz-naive Datetime to tz-aware Datetime
dto.tz_convert('US/Central')convert tz-aware Datetime Array/Index from one time zone to another
idx = pd.date_range('2023-01-01', periods=3)
idx.to_period()converts Datetime to Period
dto.round('H')round operation on the data to the specified freq
dto.floor('1min')rounds down to the nearest value
dto.ceil('1min')rounds up to the nearest value
calculations
datetime calculation - extraction and addition of dates and time
t1 = pd.to_datetime('1/1/2023 01:00')
t2 = pd.to_datetime('today')
(t2 - t1).componentsget time difference and return components(day, hour, minute, second)
(t2 - t1).secondsget only seconds component
(t2 - t1).total_seconds()get total seconds between two dates
df['date1'].dt.year - df['date2'].dt.yearcalculate difference of the years
df['date'] + pd.Timedelta(days=1)add 1 day to datetime column
df['date'] + pd.DateOffset(hours=16)add 16 hours to datetime column
pd.Timedelta(5, 'H')get timedelta - 5 hours
pd.Timedelta(1, 'd').total_seconds()get 1 day delta as seconds
select date & time
df.set_index(['date'])
df.sort_index(inplace=True, ascending=True))set date column as index and sort for consistence
df.index = df['date']set date as index and keep the column
df.loc['2023']select rows by index dates in 2023 year
df.loc['2022-7']select rows by index dates in July 2022
df.loc['2022-1-1']select rows by index dates by a given day
df.loc['2019' : '2022']select all rows between two years (inclusive)
df.loc[df['date'] > '2022-01-01']select all rows for datetime column
df.between_time('11:10','12:15')select between start and end time
df[df['date'].between('2022', '2023')]select rows by date column between two dates
df.loc['2022-7-1 11:10' : '2023-1-1 12:15' ]locate by timestamps
pd.Interval(t1, t2).lengthget interval length between two timestamps
pd.Interval(t1, t2).overlaps(pd.Interval(t3, t4))check if two periods overlaps
time zone
pd.Timestamp.now()naive local time
pd.Timestamp.utcnow()timezone aware (UTC)
pd.Timestamp.now(tz='Europe/Rome').tz_localize(None)naive local time
pd.Timestamp.now(tz='Europe/Rome')timezone aware local time
pd.Timestamp.utcnow().tz_localize(None) remove the timezone information but converting to UTC
pd.Timestamp.utcnow().tz_convert(None)removes the timezone information resulting in naive local
dto.dt.tz_localize('+0100')localize using offset
read_csv
read_csv - parsing dates
pd.read_csv('test.csv', parse_dates = ['end_date'])try parsing columns each as a separate date column
pd.read_csv('test.csv', parse_dates = [['yy', 'mm', 'dd']])combine columns yy,mm,dd and parse as a single date column
pd.read_csv('test.csv', parse_dates = {'date1': ['yy', 'mm', 'dd']})parse columns yy, mm, dd as date and call result ‘date1’
pd.read_csv('test.csv', dayfirst = True)DD/MM format dates, international and European format
pd.read_csv('test.csv', keep_date_col = True)if parse_dates then keep the original columns
date & time format
Data and time directives for formatting
from datetime import datetime
now = datetime.now()
now.strftime('%X')14:56:48 || get current time and format it
%aThu || Abbreviated weekday (Sun)
%AThursday || Weekday (Sunday)
%bJan || Abbreviated month name (Jan)
%Bjanuary || Month name (January)
%cThu Jan 5 14:50:48 2023 || Date and time
%d5 || Day (leading zeros) (01 to 31)
%H14 || 24 hour (leading zeros) (00 to 23)
%I2 || 12 hour (leading zeros) (01 to 12)
%j5 || Day of year (001 to 366)
%m1 || Month (01 to 12)
%M53 || Minute (00 to 59)
%pPM || AM or PM
%S48 || Second (00 to 29)
%U1 || Week number (00 to 53)
%w4 || Weekday (0 - Sun to 6 - Sat)
%W1 || Week number (00 to 53)
%x01/05/23 || Date
%X14:56:48 || Time
%y23 || Year without century (00 to 99)
%Y2023 || Year (2008)
%ZGMT || Time zone (GMT)
%%% || A literal % character
Working with datetime
Here are some common tasks you might want to do with datetime data in Pandas:
- Create a datetime column in a Pandas DataFrame - we can use the
pd.to_datetimemethod to convert a column of strings to a column of datetime objects.
For example:
import pandas as pd
df = pd.DataFrame({'date_string': ['2022-01-01', '2022-01-02', '2022-01-03']})
df['date'] = pd.to_datetime(df['date_string'])
result is a datetime Series and new column:
0 2022-01-01
1 2022-01-02
2 2022-01-03
Name: date_string, dtype: datetime64[ns]
- Extract the year, month, or day from a datetime column - we can use the
dtattribute of a datetime columns to extract the year, month, or day as a separate column.
For example:
df['year'] = df['date'].dt.year
df['month'] = df['date'].dt.month
df['day'] = df['date'].dt.day
- Filter a DataFrame by a datetime column:
dtattribute can be used to filter a DataFrame by a specific date range.
For example:
# filter rows where the date year is 2023
df_2023 = df[df['date'].dt.year == 2023]
# filter rows where the date is in January 2023
df_january_2023 = df[(df['date'].dt.year == 2023) & (df['date'].dt.month == 1)]
- Aggregate data by a datetime column - we can use the
groupby()method to aggregate data by a datetime column.
Example:
# calculate the mean value of a column for each year
df.groupby(df['date'].dt.year)['value'].mean()
# calculate the sum of a column for each month
df.groupby(df['date'].dt.month)['value'].sum()
