In this short tutorial, we'll see how to extract tables from PDF files with Python and Pandas.
We will cover two cases of table extraction from PDF:
(1) Simple table with tabula-py
from tabula import read_pdf
df_temp = read_pdf('china.pdf')
(2) Table with merged cells
import pandas as pd
html_tables = pd.read_html(page)
Let's cover both examples in more detail as context is important.
Nice video on the topic: Easily extract tables from websites with pandas and python
Notebook: Scrape wiki tables with pandas and python.ipynb
1: Extract tables from PDF with Python
In this example we will extract multiple tables from remote PDF file: china.pdf.
We will use library called: tabula-py which can be installed by:
pip install tabula-py
The .pdf file contains 2 table:
- smaller one
- bigger one with merged cells
from tabula import read_pdf
file = 'https://raw.githubusercontent.com/tabulapdf/tabula-java/master/src/test/resources/technology/tabula/china.pdf'
df_temp = read_pdf(file, stream=True)
After reading the data we can get a list of DataFrames which contain table data.
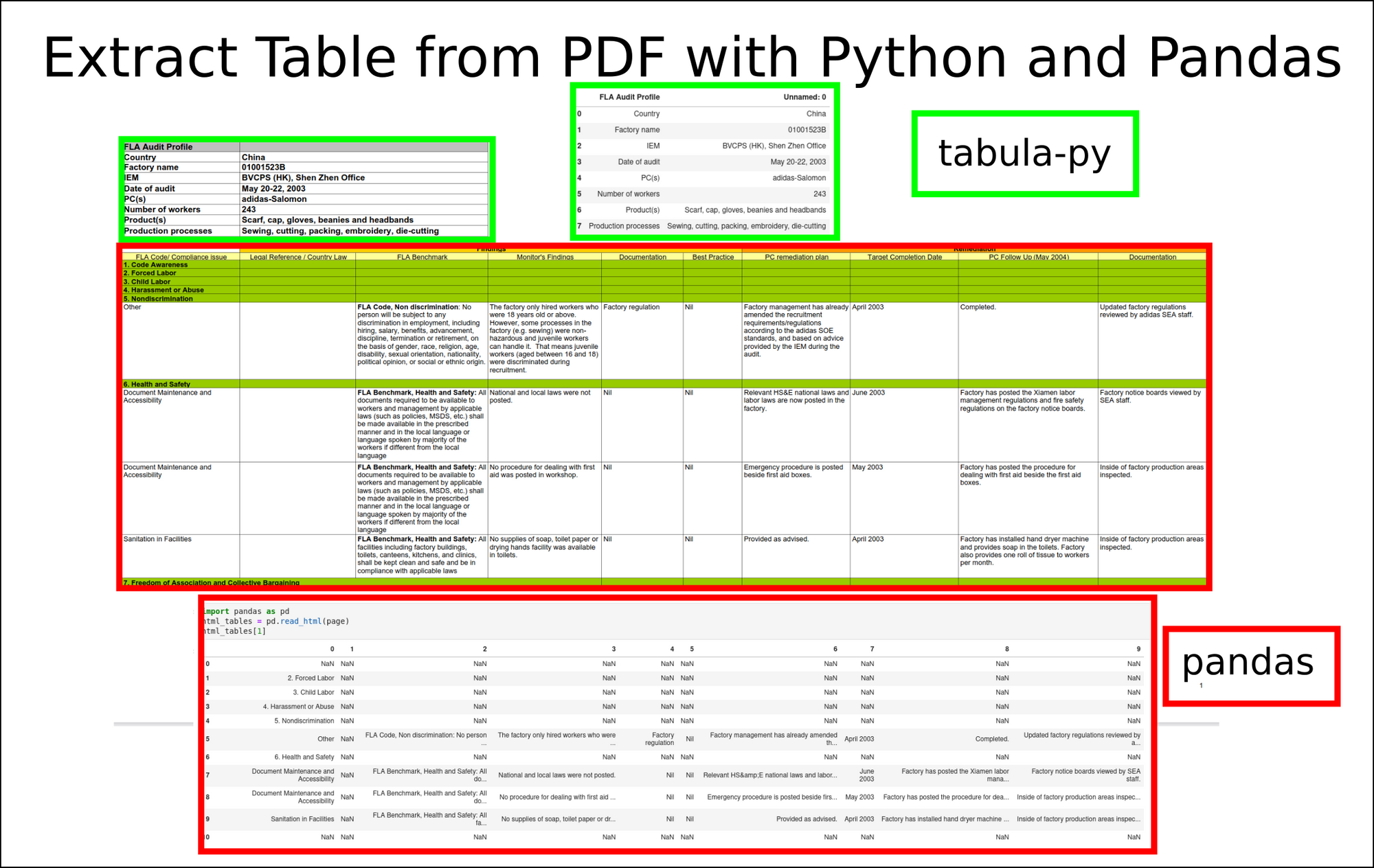
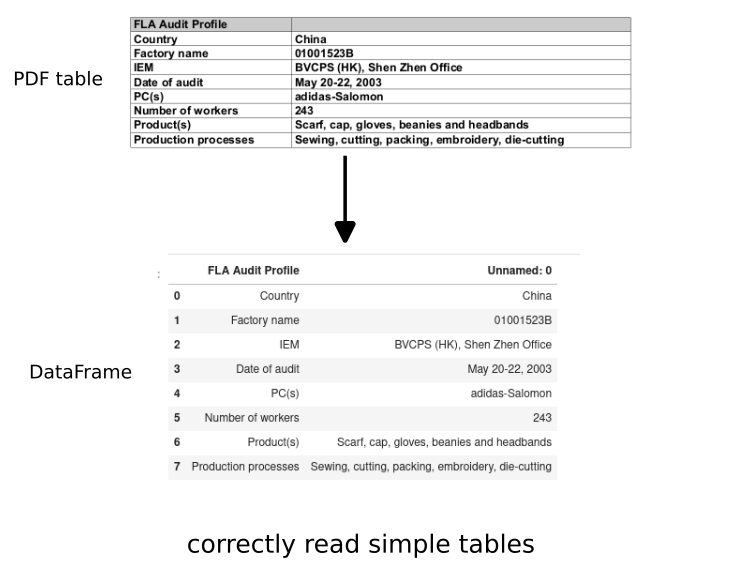
Let's check the first one:
| FLA Audit Profile | Unnamed: 0 | |
|---|---|---|
| 0 | Country | China |
| 1 | Factory name | 01001523B |
| 2 | IEM | BVCPS (HK), Shen Zhen Office |
| 3 | Date of audit | May 20-22, 2003 |
| 4 | PC(s) | adidas-Salomon |
| 5 | Number of workers | 243 |
| 6 | Product(s) | Scarf, cap, gloves, beanies and headbands |
| 7 | Production processes | Sewing, cutting, packing, embroidery, die-cutting |
Which is the exact match of the first table from the PDF file.
While the second one is a bit weird. The reason is because of the merged cells which are extracted as NaN values:
| Unnamed: 0 | Unnamed: 1 | Unnamed: 2 | Findings | Unnamed: 3 | |
|---|---|---|---|---|---|
| 0 | FLA Code/ Compliance issue | Legal Reference / Country Law | FLA Benchmark | Monitor's Findings | NaN |
| 1 | 1. Code Awareness | NaN | NaN | NaN | NaN |
| 2 | 2. Forced Labor | NaN | NaN | NaN | NaN |
| 3 | 3. Child Labor | NaN | NaN | NaN | NaN |
| 4 | 4. Harassment or Abuse | NaN | NaN | NaN | NaN |
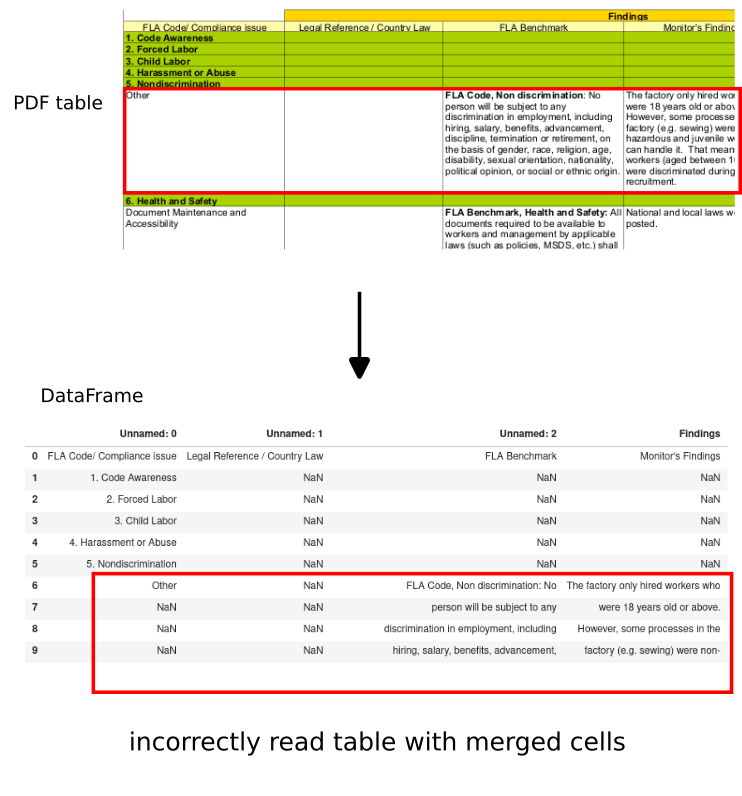
How to workaround this problem we will see in the next step.
Some cells are extracted to multiple rows as we can see from the image:
2: Extract tables from PDF - keep format
Often tables in PDF files have:
- strange format
- merged cells
- strange symbols
Most libraries and software are not able to extract them in a reliable way.
To extract complex table from PDF files with Python and Pandas we will do:
- download the file (it's possible without download)
- convert the PDF file to HTML
- extract the tables with Pandas
2.1 Convert PDF to HTML
First we will download the file from: china.pdf.
Then we will convert it to HTML with the library: pdftotree.
import pdftotree
page = pdftotree.parse('china.pdf', html_path=None, model_type=None, model_path=None, visualize=False)
library can be installed by:
pip install pdftotree
2.2 Extract tables with Pandas
Finally we can read all the tables from this page with Pandas:
import pandas as pd
html_tables = pd.read_html(page)
html_tables[1]
Which will give us better results in comparison to tabula-py

2.3 HTMLTableParser
As alternatively to Pandas, we can use the library: html-table-parser-python3 to parse the HTML tables to Python lists.
from html_table_parser.parser import HTMLTableParser
p = HTMLTableParser()
p.feed(page)
print(p.tables[0])
it convert the HTML table to Python list:
[['', ''], ['Country', 'China'], ['Factory name', '01001523B'], ['IEM', 'BVCPS (HK), Shen Zhen Office'], ['Date of audit', 'May 20-22, 2003'], ['PC(s)', 'adidas-Salomon'], ['Number of workers', '243'], ['Product(s)', 'Scarf, cap, gloves, beanies and headbands']]
Now we can convert the list to Pandas DataFrame:
import pandas as pd
pd.DataFrame(p.tables[1])
To install this library we can do:
pip install html-table-parser-python3
There are two differences to Pandas:
- returns list of values
- instead of NaN values - there are empty strings
3. Python Libraries for extraction from PDF files
Finally let's find a list of useful Python libraries which can help in PDF parsing and extraction:
3.1 Python PDF parsing
- tabula-py - Simple wrapper for tabula-java, read tables from PDF into DataFrame
- camelot-py - PDF Table Extraction for Humans
- pdfminer - PDF parser and analyzer
- PyPDF2 - A pure-python PDF library capable of splitting, merging, cropping, and transforming PDF files
3.2 Parse HTML tables
- html-table-parser-python3 - parse HTML tables with Python 3 to list of values
- tablextract - extracts the information represented in any HTML table
- pdftotree - convert PDF into hOCR with text, tables, and figures being recognized and preserved.
- pandas.read_html
- html-table-extractor - A python library for extracting data from html table
- py-html-table - Python library to extract data from HTML Tables with rowspan
3.3 Example PDF files
Finally you can find example PDF files where you can test table extraction with Python and Pandas: