In this short guide, I'll show you how to extract domain from a URL column in Pandas DataFrame. You can also find how to extract netloc, schema, path, params. So at the end you will get:
['https://www.datascientyst.com/cheatsheet','https://www.softhints.com/python']
to:
0 (https, www.datascientyst.com, /cheatsheet, , , )
1 (https, www.softhints.com, /python, , , )
Name: urls, dtype: object
or extracting only domains:
0 www.datascientyst.com
1 www.softhints.com
Name: urls, dtype: object
Setup
Let's have DataFrame with URL column from which we will extract list of domains:
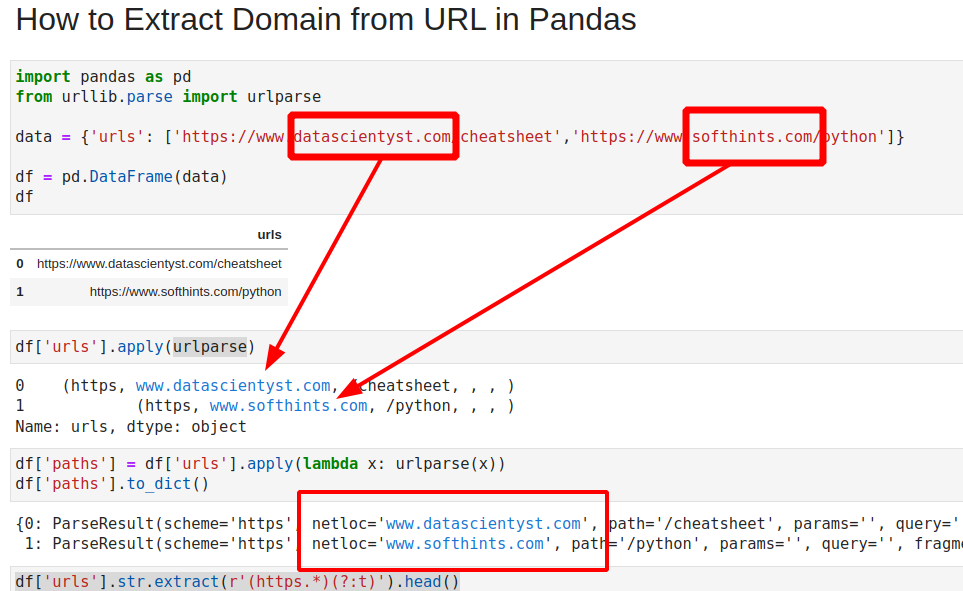
import pandas as pd
data = {'urls': ['https://www.datascientyst.com/cheatsheet','https://www.softhints.com/python']}
df = pd.DataFrame(data)
DataFrame looks like:
| urls | |
|---|---|
| 0 | https://www.datascientyst.com/cheatsheet |
| 1 | https://www.softhints.com/python |
Step 1: Extract domain from URL - urlparse
First way to extract domain from URL in Python is library - urlparse:
from urllib.parse import urlparse
df['urls'].apply(urlparse)
This will extract all information as Series of tuples:
0 (https, www.datascientyst.com, /cheatsheet, , , )
1 (https, www.softhints.com, /python, , , )
Name: urls, dtype: object
To extract only the netloc or the domain we can use:
df['urls'].apply(lambda x: urlparse(x)[1])
extracted netloc-s from the URL column:
0 www.datascientyst.com
1 www.softhints.com
Name: urls, dtype: object
We can extract the full ParseResult from the urlparse library by:
df['paths'] = df['urls'].apply(lambda x: urlparse(x))
df['paths'].to_dict()
result is full URL information:
{0: ParseResult(scheme='https', netloc='www.datascientyst.com', path='/cheatsheet', params='', query='', fragment=''),
1: ParseResult(scheme='https', netloc='www.softhints.com', path='/python', params='', query='', fragment='')}
Step 2: Extract domain from URL - regex
We can use regular expression in order to extract patterns from the URL columns. Pandas offers .str.extract method:
df['urls'].str.extract(r'https://(.*)/')
would extract the domains plus the subdomains if any:
| 0 | |
|---|---|
| 0 | www.datascientyst.com |
| 1 | www.softhints.com |
Or we can match up to symbol without extracting the symbol. In this case we will search for anything until we match char t:
df['urls'].str.extract(r'(https.*)(?:t)').head()
result:
| 0 | |
|---|---|
| 0 | https://www.datascientyst.com/cheatshee |
| 1 | https://www.softhints.com/py |
Conclusion
We saw two different ways how to parse URL information with Python and Pandas.
We can extract from Pandas DataFrame information like:
- scheme='https'
- netloc='www.datascientyst.com'
- path='/cheatsheet'
- params=''
- query=''
- fragment=''