Common Pandas error - error: nothing to repeat at position 0 can be result of several operations:
- bad regular expression
- reading CSV file with incorrect separator
Fix error: nothing to repeat at position 0
To fix error:
error: nothing to repeat at position 0
First we need to identify what is the reason for this error.
Once we know the reason the solutions might be:
- change -
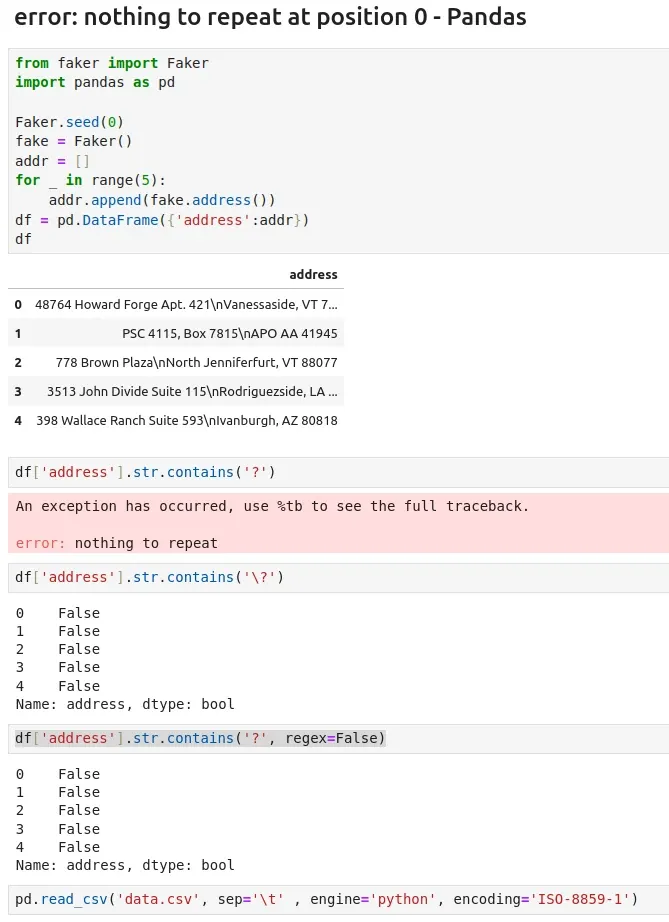
.str.contains('?')to.str.contains('?', regex=False) - change the
read_csv()sepators, encoding etc:, sep='\t', engine='python', encoding='ISO-8859-1'
Data
Suppose we have data like the one below:
from faker import Faker
import pandas as pd
Faker.seed(0)
fake = Faker()
addr = []
for _ in range(5):
addr.append(fake.address())
df = pd.DataFrame({'address':addr})
| address | |
|---|---|
| 0 | 48764 Howard Forge Apt. 421\nVanessaside, VT 79393 |
| 1 | PSC 4115, Box 7815\nAPO AA 41945 |
| 2 | 778 Brown Plaza\nNorth Jenniferfurt, VT 88077 |
| 3 | 3513 John Divide Suite 115\nRodriguezside, LA 93111 |
| 4 | 398 Wallace Ranch Suite 593\nIvanburgh, AZ 80818 |
Example - bad regex
If we try to search for a question mark we will end with Pandas error: error: nothing to repeat at position 0.
df['address'].str.contains('?')
The solution is either to escape the question mark or use regex=False:
df['address'].str.contains('\?')
df['address'].str.contains('?', regex=False)
Fix - read_csv
To fix the same error if we get it during reading CSV file by method read_csv file we can use parameters like:
pd.read_csv('data.csv', sep=''\*,\*'' , engine='python', encoding='ISO-8859-1')
Why do we get this error for read_csv? The reason is that some characters are special and treated in a different way. So we may need to escape them:
addition, separators longer than 1 character and different from '\s+' will be interpreted as regular expressions and will also force the use of the Python parsing engine. Note that regex delimiters are prone to ignoring quoted data. Regex example: '\r\t'.
Output