








Today is the first day of the World Cup 2022 which takes place in Qatar from 20-th of November to 18-th of December. 32 teams will compete in eight groups for the prize. In this post we will use data-driven approach to analyze the teams and what people twit for the new football event.
What we can learn from this post is how to extract tweets with Python library tweepy and use Pandas to analyse them. This article will walk through how to collect meta data, scrape tweets and read all tweets into a Pandas DataFrame. Because the Twitter setup and authentication process is complex, we will not cover it in details.
This is a sample data science project for confident beginners :)
Requirements
Libraries needed for this project:
pip install tweepy
pip install python-dotenv
pip install pycountry
pip install emoji-country-flag
1. Collect meta data
The first part of the process is collecting finalist countries and their flags. If you haven't used Pandas to scrape web before, use the following links:
1.1 Collect finalists
Once we find the page where we can collect data, we can use it in the next Python code:
from pandas.io.html import read_html
page = 'https://en.wikipedia.org/wiki/2022_FIFA_World_Cup_qualification'
wikitables = read_html(page)
len(wikitables)
Method read_html reads HTML tables into a list of DataFrame objects.
The result is 30.
As we can see the page: 2022 FIFA World Cup qualification contains 30 tables. The one which contains our data is available under number 1 - we can find that by inspecting the page or displaying DataFrames:
df_fin = wikitables[1]
df_fin.head()
Now we have all countries which plays on the World Cup 2022 as Pandas DataFrame:
| Team | Method ofqualification | Date ofqualification | Totaltimesqualified | Lasttimequalified | Currentconsecutiveappearances | Previous bestperformance | |
|---|---|---|---|---|---|---|---|
| 0 | Qatar | Hosts | 2 December 2010 | 1 | – | 1 | – |
| 1 | Germany | UEFA Group J winners | 11 October 2021 | 20[a] | 2018 | 18 | Winners (1954, 1974, 1990, 2014) |
| 2 | Denmark | UEFA Group F winners | 12 October 2021 | 6 | 2018 | 2 | Quarter-finals (1998) |
| 3 | Brazil | CONMEBOL winners | 11 November 2021 | 22 | 2018 | 22 | Winners (1958, 1962, 1970, 1994, 2002) |
| 4 | France | UEFA Group D winners | 13 November 2021 | 16 | 2018 | 7 | Winners (1998, 2018) |
1.2 Get country flags
Python offers elegant way to collect information about counrtries like:
- flag
- abbreviations
- official name
The first library is named: pycountry. This Python library provides the ISO databases for the standards:
- Languages
- Countries
- Subdivisions of countries
- Currencies
Currently contains about 250 countries. From this library we would use fuzzy matching to collect the country details:
import pycountry
pycountry.countries.search_fuzzy('Brazil')
which results into:
[Country(alpha_2='BR', alpha_3='BRA', flag='🇧🇷', name='Brazil', numeric='076', official_name='Federative Republic of Brazil')]
For our needs we will collect the flags for the 32 teams on the World Cup:
countries = []
for fin in finalists:
try:
country = pycountry.countries.search_fuzzy(fin)[0]
flag = country.flag
country = {fin:flag}
except:
print(fin)
countries.append(country)
print(countries)
Which results into:
England
[{'Qatar': '🇶🇦'}, {'Germany': '🇩🇪'}, {'Denmark': '🇩🇰'}, {'Brazil': '🇧🇷'}, {'France': '🇫🇷'}, {'Belgium': '🇧🇪'},
{'Serbia': '🇷🇸'}, {'Spain': '🇪🇸'}, {'Croatia': '🇭🇷'}, {'Switzerland': '🇨🇭'}, {'Switzerland': '🇨🇭'}, {'Netherlands': '🇳🇱'},
{'Argentina': '🇦🇷'}, {'Iran': '🇮🇷'}, {'South Korea': '🇰🇷'}, {'Saudi Arabia': '🇸🇦'}, {'Japan': '🇯🇵'}, {'Uruguay': '🇺🇾'},
{'Ecuador': '🇪🇨'}, {'Canada': '🇨🇦'}, {'Ghana': '🇬🇭'},
{'Senegal': '🇸🇳'}, {'Poland': '🇵🇱'}, {'Portugal': '🇵🇹'}, {'Tunisia': '🇹🇳'}, {'Morocco': '🇲🇦'}, {'Cameroon': '🇨🇲'},
{'United States': '🇺🇸'}, {'Mexico': '🇲🇽'}, {'Wales': '🇦🇺'}, {'Australia': '🇦🇺'}, {'Costa Rica': '🇨🇷'}]
There is open issue for England: search_fuzzy fails for 'England'
Alternatively we can use another library called: emoji-country-flag.
import flag
flag.flag("FR")
result:
'🇫🇷'
Finally we need to get English flag as dict {'England': '🏴'} and append it to the list.
2. Extract Tweets
For this step we are going to use library: tweepy.
Depending on the Twitter access we can use two different approaches to extract tweets:
- Essential access - Twitter API v2 endpoints only
- Elevated access - everything
2.1 Setup a Twitter Developer Account
To setup new Twitter Developer Account we can use these articles as a reference:
2.2 Essential access
Using this approach we need only BEARER_TOKEN from Twitter. So we can search for tweets by query '#FIFAWorldCup'.
To make this code work you need to replace os.environ["BEARER_TOKEN"] with your token. Alternatively you can create .env file with the following syntax - the file should be in the same folder as the script:
API_KEY="xxx"
API_KEY_SECRET="xxx"
BEARER_TOKEN="xxx"
ACCESS_TOKEN="xxx"
ACCESS_TOKEN_SECRET="xxx"
Then to extract tweets run the following code:
import tweepy
import pandas as pd
bearer_token = os.environ["BEARER_TOKEN"]
client = tweepy.Client(bearer_token=bearer_token)
"""
More examples
https://github.com/twitterdev/getting-started-with-the-twitter-api-v2-for-academic-research/blob/main/modules/5-how-to-write-search-queries.md
"""
query = '#FIFAWorldCup'
tweets = client.search_recent_tweets(query=query, tweet_fields=['context_annotations', 'created_at'], max_results=10)
pd.DataFrame(tweets.data)
By default the Twitter API will return max of 100 results. In order to get more than 100 tweets we are using built-in tweepy.Paginator:
import tweepy
client = tweepy.Client(bearer_token=bearer_token)
query = '#FIFAWorldCup'
tweets = tweepy.Paginator(client.search_recent_tweets, query=query,
tweet_fields=['context_annotations', 'created_at'], max_results=100).flatten(limit=10000)
ls = []
for tweet in tweets:
ls.append(tweet)
import pandas as pd
df = pd.DataFrame(ls)
The tweets stored as Pandas DataFrame:
| created_at | id | text | |
|---|---|---|---|
| 0 | 2022-11-20 11:14:41+00:00 | 1594288115992043520 | RT @sushimmii: @rahmdess27 @BTS_twt DREAMERS BY JUNGKOOK\nDREAMERS STREAMING PARTY\n\n#Dreamers2022 #FIFAWorldCup @BTS_twt #DreamersByJungkoo… |
| 1 | 2022-11-20 11:14:41+00:00 | 1594288115895914496 | RT @FIFAWorldCup: "See you at the Opening!" - Jung Kook \n\nToday, 5.30pm local time. \n\n#Qatar2022 | #FIFAWorldCup https://t.co/3oulTUthBV |
| 2 | 2022-11-20 11:14:41+00:00 | 1594288115635539969 | @kingnyamjoon DREAMERS BY JUNGKOOK\nDREAMERS STREAMING PARTY\n\n#Dreamers2022 #FIFAWorldCup @BTS_twt #DreamersByJungkook #JungKook #정국 |
| 3 | 2022-11-20 11:14:41+00:00 | 1594288115581358081 | RT @btsarmy39521947: Jungkook 💜\nI’m so addicted with #Jungkook of \n@BTS_twt\n's new single "Dreamers" for the #FIFAWorldCup ! The lyri… |
| 4 | 2022-11-20 11:14:41+00:00 | 1594288115283214336 | RT @Bangtan_twt_com: @btssomma DREAMERS BY JUNGKOOK\nDREAMERS STREAMING PARTY\n\n#Dreamers2022 #FIFAWorldCup #DreamersByJungkook #JungK… |
2.3 Elevated access
You need to apply for Elevated access to work with the code below. Otherwise you will face an error:
Forbidden: 403 Forbidden
453 - You currently have Essential access which includes access to Twitter API v2 endpoints only. If you need access to this endpoint, you’ll need to apply for Elevated access via the Developer Portal. You can learn more here: https://developer.twitter.com/en/docs/twitter-api/getting-started/about-twitter-api#v2-access-leve
Code:
import os
import tweepy
from dotenv import load_dotenv, find_dotenv
from pathlib import Path
path='./conf/.env'
load_dotenv(dotenv_path=path,verbose=True)
consumer_key = os.environ["API_KEY"]
consumer_secret = os.environ["API_KEY_SECRET"]
access_token = os.environ["ACCESS_TOKEN"]
access_token_secret = os.environ["ACCESS_TOKEN_SECRET"]
auth = tweepy.OAuth1UserHandler(
consumer_key,
consumer_secret,
access_token,
access_token_secret
)
api = tweepy.API(auth)
tweets = api.search_tweets("World cup", tweet_mode="extended")
for tweet in tweets:
try:
print(tweet.retweeted_status.full_text)
print("=====")
except AttributeError:
print(tweet.full_text)
print("=====")
3. Analyse Extracted Data
Finally we will use data collected in previous two steps.
3.1. Finding the most mentioned countries
To find the most mentioned countries we can use loop over the teams and count the mentions:
count_team = []
for team in df_fin['Team']:
count_team.append(df[df['text'].str.contains(team)].shape[0])
df_fin['count'] = count_team
df_fin.sort_values('count', ascending=False).set_index('Team').tail(31)['count' ].plot(kind='bar')
We exlude Qatar from the chart as it has more than 3500 mentions:
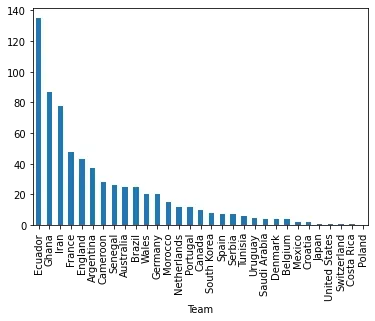
We can see that the other top mentioned country is Ecuador. This is expected as this is going to be the first game: Qatar - Ecuador.
3.2. Searching by flags
We can use flags to search in the tweets - as we know emojis are very popular in the Twitter jargon:
df[df.text.str.contains(flag.flag("FR"))].shape
df[df.text.str.contains(flag.flag("BR"))].shape
So we get that Brazile is mentioned 48 times while France is mentioned 45 times.
Conclusion
There are several new ideas we learned with this post:.
- how to easily extract tabular data with Pandas
- several new Python libraries to make your live much easier
- how to scrape tweets with few line of codes
- data-driven approach to solve everyday problems
Finally, I love the motto of 2022 World Cup:
"Expect Amazing"