








Here are several ways to sample random rows per group in Pandas:
(1) random selection per group
df.groupby('continent').apply(lambda x: x.sample(n=3))
(2) random selection per group - different size
(df
.groupby('continent')
.apply(lambda x: x.sample(n=3, replace=True))
.drop_duplicates()
)
(3) sample based on column
col = 'continent'
categories = list(df[col].dropna().unique())
for cat in categories:
if df[df[col] == cat].shape[0] > 3:
print(cat, end=' - ')
display(df[df[col] == cat].sample(3, replace=True))
The result is shown below - getting N random samples per each group on:
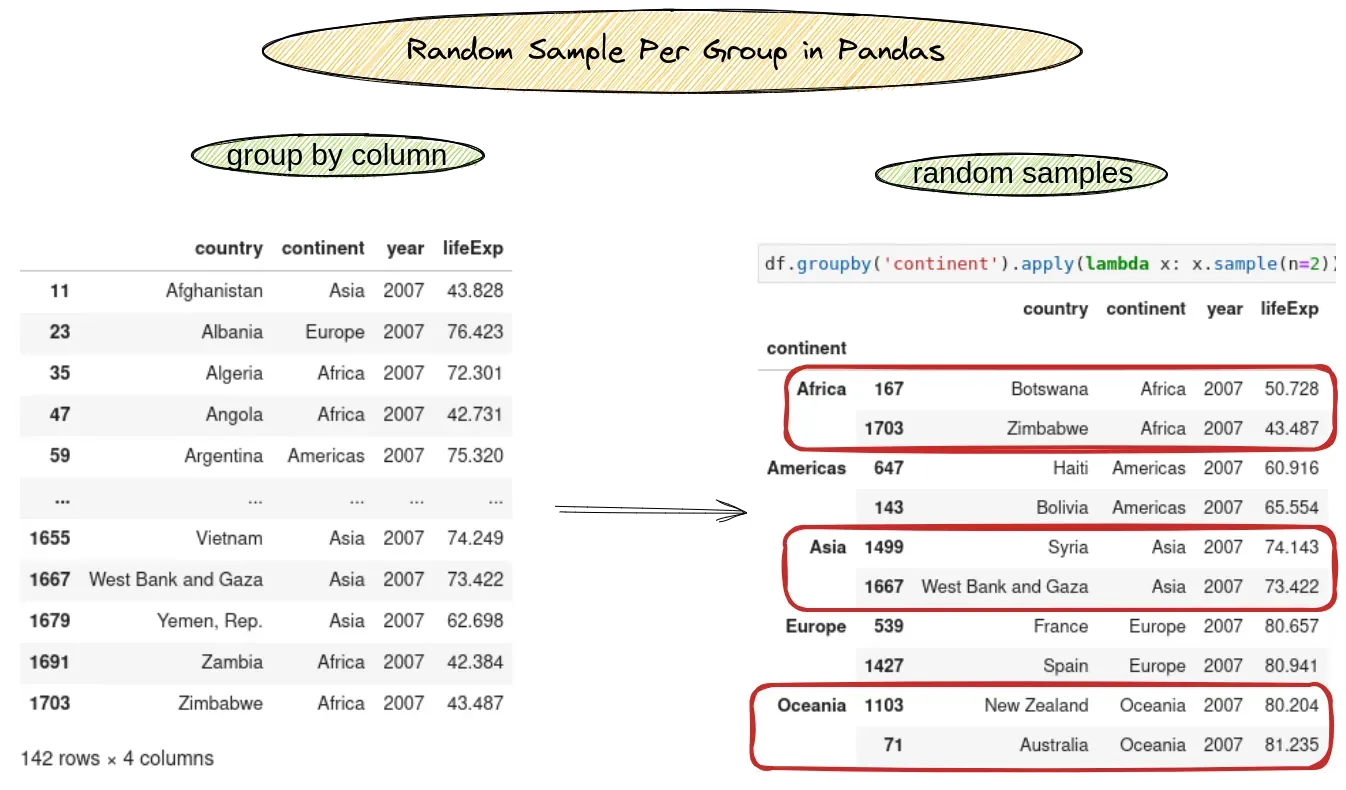
Setup
In the post, we'll use the following DataFrame, available from library plotly.
To install plotly use pip install plotly. We will create DataFrame getting info for 2007 year:
import plotly.express as px
df = px.data.gapminder().query("year == 2007")
cols = df.columns[:4]
df = df[cols]
DataFrame looks like:
| country | continent | year | lifeExp | |
|---|---|---|---|---|
| 11 | Afghanistan | Asia | 2007 | 43.828 |
| 23 | Albania | Europe | 2007 | 76.423 |
| 35 | Algeria | Africa | 2007 | 72.301 |
| 47 | Angola | Africa | 2007 | 42.731 |
| 59 | Argentina | Americas | 2007 | 75.320 |
For simplicity we will work only with the first 4 columns.
1: Random selection per group
To do random selection per group in Pandas we can:
- use
groupby()on a column(s) - and use
applyandsamplemethods:
df.groupby('continent').apply(lambda x: x.sample(n=1))
We get random country per each continent:
| country | continent | year | lifeExp | ||
|---|---|---|---|---|---|
| continent | |||||
| Africa | 1595 | Uganda | Africa | 2007 | 51.542 |
| Americas | 1211 | Peru | Americas | 2007 | 71.421 |
| Asia | 719 | Indonesia | Asia | 2007 | 70.650 |
| Europe | 527 | Finland | Europe | 2007 | 79.313 |
| Oceania | 71 | Australia | Oceania | 2007 | 81.235 |
If we try to use large sample number we will get error:
ValueError: Cannot take a larger sample than population when 'replace=False'
We will solve this error in next section
sample by group - different size
If the groups have different sizes or some groups are smaller than the selected sample number we can use repetitions. To sample with repetition we need to pass replace=True to sample() method:
df.groupby('continent').apply(lambda x: x.sample(n=3, replace=True))
This will solve the error above:
| country | continent | year | lifeExp | ||
|---|---|---|---|---|---|
| continent | |||||
| Africa | 1547 | Togo | Africa | 2007 | 58.420 |
| 347 | Congo, Rep. | Africa | 2007 | 55.322 | |
| 1571 | Tunisia | Africa | 2007 | 73.923 | |
| Americas | 251 | Canada | Americas | 2007 | 80.653 |
| 287 | Chile | Americas | 2007 | 78.553 | |
| 251 | Canada | Americas | 2007 | 80.653 | |
| Asia | 1439 | Sri Lanka | Asia | 2007 | 72.396 |
| 731 | Iran | Asia | 2007 | 70.964 | |
| 107 | Bangladesh | Asia | 2007 | 64.062 | |
| Europe | 527 | Finland | Europe | 2007 | 79.313 |
| 407 | Czech Republic | Europe | 2007 | 76.486 | |
| 1283 | Romania | Europe | 2007 | 72.476 | |
| Oceania | 1103 | New Zealand | Oceania | 2007 | 80.204 |
| 71 | Australia | Oceania | 2007 | 81.235 | |
| 1103 | New Zealand | Oceania | 2007 | 80.204 |
Get unique samples per group
Downside is that we have repetitions in the groups with smaller items. Remove duplicated rows can be done by adding .drop_duplicates():
(df
.groupby('continent')
.apply(lambda x: x.sample(n=3, replace=True))
.drop_duplicates()
)
This code shows the usage of Pandas chaining. It's easier to read and maintain.
Group by multiple columns and sample
To group by multiple columns and sample random values per each group in Pandas we can use similar code:
(df
.groupby(['continent', 'year'])
.apply(lambda x: x.sample(n=2, replace=True))
.drop_duplicates()
)
The result is multi-index with samples from each group:
| country | continent | year | lifeExp | |||
|---|---|---|---|---|---|---|
| continent | year | |||||
| Africa | 2007 | 1067 | Namibia | Africa | 2007 | 52.906 |
| 923 | Madagascar | Africa | 2007 | 59.443 | ||
| Americas | 2007 | 179 | Brazil | Americas | 2007 | 72.390 |
| 1259 | Puerto Rico | Americas | 2007 | 78.746 | ||
| Asia | 2007 | 1007 | Mongolia | Asia | 2007 | 66.803 |
| 875 | Lebanon | Asia | 2007 | 71.993 | ||
| Europe | 2007 | 1391 | Slovenia | Europe | 2007 | 77.926 |
| 1091 | Netherlands | Europe | 2007 | 79.762 | ||
| Oceania | 2007 | 71 | Australia | Oceania | 2007 | 81.235 |
| 1103 | New Zealand | Oceania | 2007 | 80.204 |
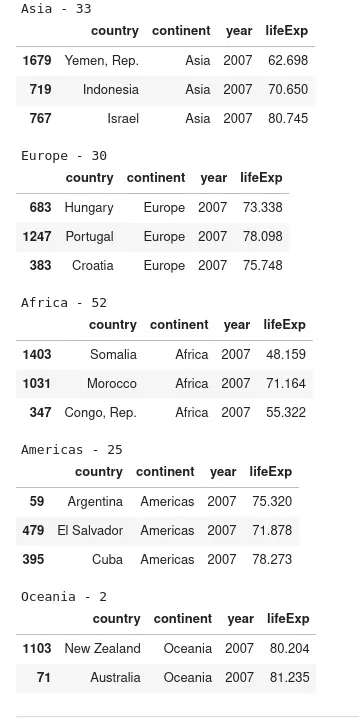
Random sample per group - for loop
If we need to add filtering or parsing logic we may use a for loop. In this way we may get different DataFrames for each sample group:
col = 'continent'
categories = list(df[col].dropna().unique())
for cat in categories:
group_size = df[df[col] == cat].shape[0]
print(cat, '-', group_size)
if group_size >= 3:
display(df[df[col] == cat].sample(3))
else:
display(df[df[col] == cat].sample(group_size))
The result is visible on the image below:
Conclusion
In this article, we looked at different ways for sampling random items per group in Pandas and Python. We focused on equal sampling, but also covered sampling from groups with different sizes.
Finally we saw how to exclude, filter or parse some groups when doing random sampling. We briefly introduce Pandas chaining - a nice technique for writing better and more readable Pandas code.