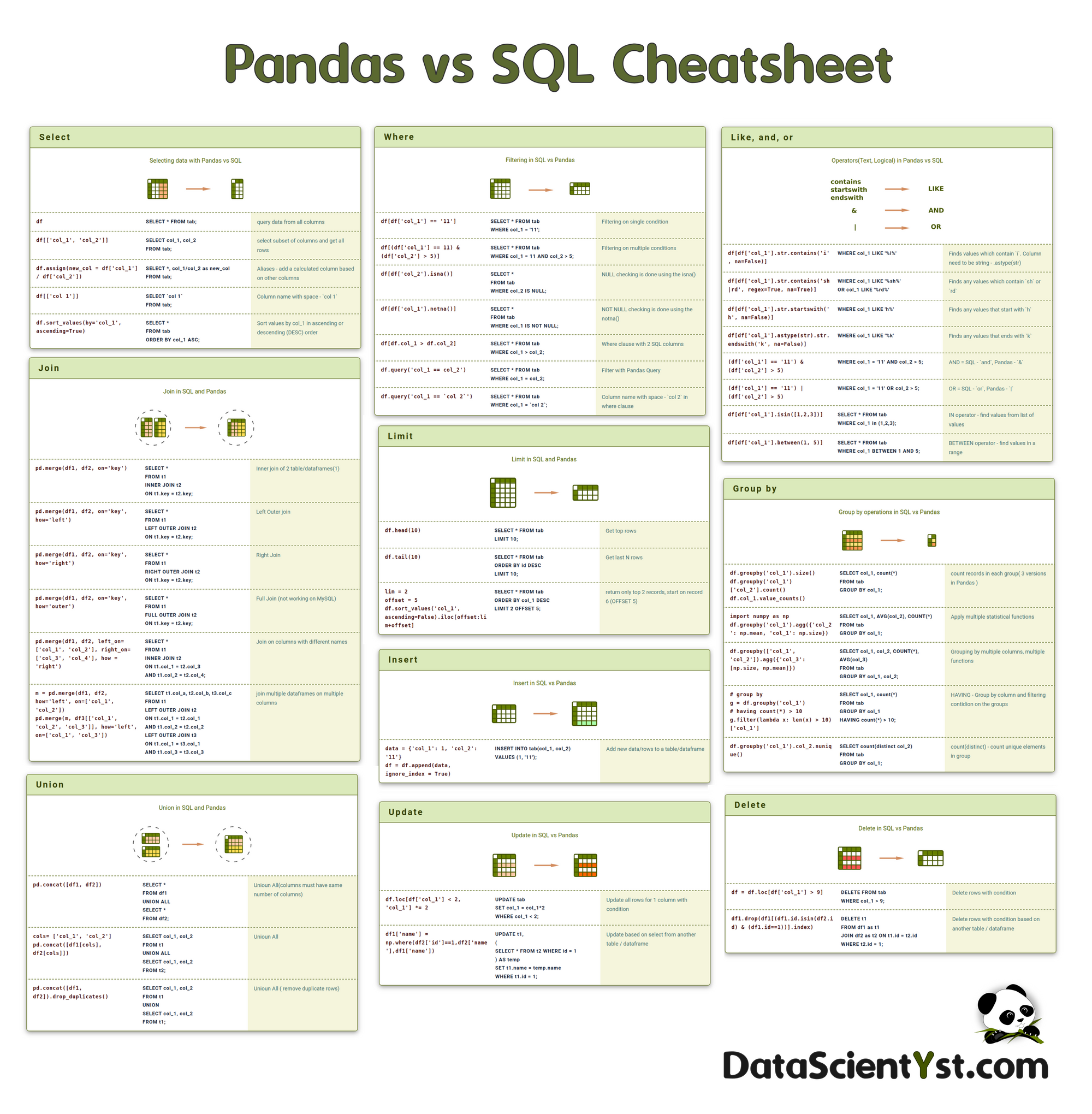
With this SQL & Pandas cheat sheet, we'll have a valuable reference guide for Pandas and SQL. We can convert or run SQL code in Pandas or vice versa. Consider it as Pandas cheat sheet for people who know SQL.
The cheat sheet covers basic querying tables, filtering data, aggregating data, modifying and advanced operations. It includes the most popular operations which are used on a daily basis with SQL or Pandas.
Keep reading until the end for bonus tips and conversion between Pandas and SQL.
Select

dfdf[['col_1', 'col_2']]df.assign(new_col = df['col_1'] / df['col_2'])df[['col 1']]df.sort_values(by='col_1', ascending=True)Where

df[df['col_1'] == '11']df[(df['col_1'] == 11) &
(df['col_2'] > 5)]df[df['col_2'].isna()]df[df['col_1'].notna()]df[df.col_1 > df.col_2]df.query('col_1 == col_2')df.query('col_1 == `col 2`')Like, and, or

df[df['col_1'].str.contains('i', na=False)]df[df['col_1'].str.contains('sh|rd', regex=True, na=True)]df[df['col_1'].str.startswith('h', na=False)]df[df['col_1'].astype(str).str.endswith('k', na=False)](df['col_1'] == '11') & (df['col_2'] > 5)(df['col_1'] == '11') | (df['col_2'] > 5)df[df['col_1'].isin([1,2,3])]df[df['col_1'].between(1, 5)]Group by

df.groupby('col_1').size()
df.groupby('col_1')['col_2'].count()
df.col_1.value_counts()import numpy as np
df.groupby('col_1').agg({'col_2': np.mean, 'col_1': np.size})df.groupby(['col_1', 'col_2']).agg({'col_3': [np.size, np.mean]})# group by
g = df.groupby('col_1')
# having count(*) > 10
g.filter(lambda x: len(x) > 10)['col_1']df.groupby('col_1').col_2.nunique()Join

pd.merge(df1, df2, on='key')pd.merge(df1, df2, on='key', how='left')pd.merge(df1, df2, on='key', how='right')pd.merge(df1, df2, on='key', how='outer')pd.merge(df1, df2, left_on= ['col_1', 'col_2'], right_on= ['col_3', 'col_4'], how = 'right')m = pd.merge(df1, df2, how='left', on=['col_1', 'col_2'])
pd.merge(m, df3[['col_1', 'col_2', 'col_3']], how='left', on=['col_1', 'col_3'])Union

pd.concat([df1, df2])cols= ['col_1', 'col_2']
pd.concat([df1[cols], df2[cols]])pd.concat([df1, df2]).drop_duplicates()Limit

df.head(10)
df.tail(10)lim = 2
offset = 5
df.sort_values('col_1', ascending=False).iloc[offset:lim+offset]Update

df.loc[df['col_1'] < 2, 'col_1'] *= 2df1['name'] = np.where(df2['id']==1,df2['name'],df1['name'])Delete

df = df.loc[df['col_1'] > 9]df1.drop(df1[(df1.id.isin(df2.id) & (df1.id==1))].index)Insert

data = {'col_1': 1, 'col_2': '11'}
df = df.append(data, ignore_index = True)Now we can explore the conversion between Pandas and SQL.
The SQL syntax is based and tested on MySQL 8.
Additional resources:
Pandas equivalent of SQL
Table below shows the most used equivalents between SQL and Pandas:
| Category | Pandas | SQL |
|---|---|---|
| Data Structure | DataFrames, Series | Tables, Row, Column |
| Querying | .loc , .iloc , boolean indexing | SELECT, WHERE |
| Filtering | .query() , boolean indexing | WHERE |
| Sorting | .sort_values() , .sort_index() | ORDER BY |
| Grouping | .groupby() , .agg() | GROUP BY, AGGREGATE |
| Joins | .merge() , .join(), .concat() | JOIN, UNION |
| Aggregations | .agg() , .apply() | AGGREGATE |
| Data Transformation | .apply() , .map() , .replace() | replace(column, 'old', 'new') |
| Count Unique | .nunique(), .agg(['count', 'nunique']) | count(distinct) |
| Data Cleaning | .dropna() , .fillna() | IS NULL; IS NOT NULL; |
| Data Type Conversion | .astype() | CAST |
Differences between SQL and Pandas
Usually there are multiple ways to achieve something in Pandas or SQL. Pandas offers a bigger variety of options.
Often the solution depends on the performance.
There are some key differences when you work with SQL or Pandas:
Join in SQL vs Pandas
(1) In Pandas if both key columns contain rows with NULL value, those rows will be matched against each other.
This is not the case for SQL join behavior and can lead to unexpected results in Pandas
Copies vs. in place operations
Usually in Pandas operations return copies of the Series/DataFrame. To change this behavior we can use:
df.sort_values("col_1", inplace=True)
Create a new DataFrame:
sorted_df = df.sort_values("col1")
or update the original one:
df = df.sort_values("col1")
Pandas to SQL
To convert or export Pandas DataFrame to SQL we can use method: to_sql():
There are several important parameters which need to be used for this method:
name- table name in the databasecon- DB connection. sqlalchemy.engine.(Engine or Connection) or sqlite3.Connectionif_exists- behavior if the table exists in the DBindex- convert DataFrame index to a table columnchunksize- number of rows in each batch to be written at a time
A very basic example is given below:
from sqlalchemy import create_engine
engine = create_engine('sqlite://', echo=False)
df = pd.DataFrame({'name' : ['User 1', 'User 2', 'User 3']})
df.to_sql('users', con=engine)
We can check results by using SQL query like:
engine.execute("SELECT * FROM users").fetchall()
result:
[(0, 'User 1'), (1, 'User 2'), (2, 'User 3')]
The full documentation is available on this link: to_sql()
Pandas from SQL
Pandas offers method read_sql() to get data from SQL or DB to a DataFrame or Series.
The method can be used to read SQL connection and fetch data:
pd.read_sql('SELECT col_1, col_2 FROM tab', conn)
where conn is SQLAlchemy connectable, str, or sqlite3 connection.
To find more you can check: pandas.read_sql()
Pandas and SQL with SQLAlchemy and PyMySQL
Alternatively we can convert SQL table to Pandas DataFrame with SQLAlchemy and PyMySQL.
To do so check: How to Convert MySQL Table to Pandas DataFrame / Python Dictionary
It includes many different step by step examples and options.
You can find how to connect Python to SQL using libraries - SQLAlchemy and PyMySQL.
Run SQL code in Pandas
To run SQL syntax in Python and Pandas we need to install Python package - pandasql by:
pip install -U pandasql
The package allows us to query Pandas DataFrames using SQL syntax.
It uses SQLite syntax. More information can be found here - pandasql.
Below we can see a basic example of running SQL syntax to Pandas DataFrame :
from pandasql import sqldf
import pandas as pd
q = "SELECT * FROM df LIMIT 5"
sqldf(q, globals())
Method sqldf() requires 2 parameters:
- the SQL query
globals()orlocals()function
Generate SQL statements in Pandas
SQL create table
To generate SQL statements from Pandas DataFrame We can use the method pd.io.sql.get_schema().
So the get the create SQL statement for a given DataFrame we can use:
pd.io.sql.get_schema(df.reset_index(), 'tab')
where 'tab' is the name of the DB table.
SQL insert table
Generating SQL insert statements from a DataFrame can be achieved by:
sql_insert = []
for index, row in df.iterrows():
sql_insert.append('INSERT INTO `tab` ('+ str(', '.join(df.columns))+ ') VALUES '+ str(tuple(row.values)))
Where:
dfis the name of the source DataFrametabis the target table
We are iterating over all rows of the DataFrame and generating insert statements.
Conclusion
We covered basic and advanced operations with Pandas and SQL. You can use this to quickly transfer SQL to Pandas and the reverse.
If you like content like this - make sure to subscribe to get the latest updates and resources. This post is only a part from a serires related to cheat sheets related to data science.