








1. Overview
Do you want to create a test data set with fake data in Python and Pandas? Pandas in combination with Faker ease creation of test DataFrames with fake and safe for sharing data.
Final output will be DataFrame which can be exported to:
- CSV / Excel
- JSON
- XML
- SQL inserts
- or text file
High quality test data might be crucial for the success of a given product. On the other hand, using sensitive data might cause legal issues. So the way to go is to create high quality fake data in Pandas and Python.
2. Setup
First we need install additional library - Faker:
by:
pip install Faker
This library can generate data by several providers:
- standard - few examples below
- bank
- addresses
- person
- community
- music
- vehicle
- locales
- Locale en_US
- faker.providers.address
- faker.providers.automotive
- Locale es
- faker.providers.address
- faker.providers.person
- Locale en_US
3. Generate data with Faker
We are going to cover the most popular use case of Faker. This step will explain different techniques in detail. To generate good data you need to apply one or several from them.
3.1. Locales - country specific data
Faker uses locales in order to generate country specific data like names and addresses. Generating Italian names:
from faker import Faker
fake = Faker('it_IT')
for _ in range(5):
print(fake.name())
result:
Liliana Vespa
Sig.ra Vanessa Malacarne
Gemma Fioravanti
Vittorio Antonello
Sandro Trebbi
You can generate data for multiple locales - Italy, US and Japan:
from faker import Faker
fake = Faker(['it_IT', 'en_US', 'ja_JP'])
for _ in range(10):
print(fake.name())
this will result into:
高橋 聡太郎
藤井 桃子
Aurora Scaramucci
Sarah Beltran
Rosina Durante
Sig.ra Melina Morgagni
佐藤 修平
林 修平
Charles Marks
Lazzaro Ammaniti
3.2. Dynamic Providers - custom data
Faker offers an elegant way of generating data from a custom set of elements. Let say that you like to generate fake skills from next set of words:
- "Python"
- "Pandas"
- "Linux"
Dynamic providers are the Faker way to generate custom data:
skill_provider = DynamicProvider(
provider_name="skills",
elements=["Python", "Pandas", "Linux", "SQL", "Data Mining"],
)
fake = Faker('en_US')
fake.add_provider(skill_provider)
fake.skills()
3.3. Numbers and ranges
Generating numbers and ranges is fine with pure Python. The below examples show how to generate random integer between: 0 and 15:
random.randint(0,15)
and random numbers in range with steps:
random.randrange(75000,150000, 5000)
3.4. Dates
For dates we can use the Faker methods - date(). It accepts format, start and end time:
fake.date(pattern="%Y-%m-%d", end_datetime=datetime.date(1995, 1,1))
3.5. Correlated Data
Generation of correlated data is very important for test quality. What does it mean correlated fake data? Generating pairs of country and city should be correlated:
- US and Paris - not correlated
- US and NY - correlated
The same is for:
- names and email
- birth date and experience
- nationality and native language
- experience and salary
Locales
In most cases custom solutions are required in order to get meaningful data. For example by using locales:
from faker import Faker
en_us_faker = Faker('en_US')
it_it_fake = Faker('it_IT')
print(f'{en_us_faker.city()}, USA')
print(f'{it_it_fake.city()}, Italy')
result would be:
- East Jonathanbury, USA
- Biagio calabro, Italy
Customization
Another option is by using customization. They are described here: Faker Customization
4. Define the output list of fields
Next we should define what fields we need for the final data set.
In this article we are going to generate personal data - employees with names, skills and salaries.
The list of fields for the final data set is:
- first name
- last name
- birth date
- experience
- start year
- salary
- main skill
- nationality
- city
Add description for each field if needed like:
- first name - Italian and American names
- birth date - dates between 1990 and 2000
5. Create DataFrame with Fake Data
Finally let's check how to generate the fake data and then stored it to a DataFrame. The code below will generate 50 records of personal fake data:
import csv
import pandas as pd
from faker import Faker
import datetime
import random
from faker.providers import DynamicProvider
skill_provider = DynamicProvider(
provider_name="skills",
elements=["Python", "Pandas", "Linux", "SQL", "Data Mining"],
)
def fake_data_generation(records):
fake = Faker('en_US')
employee = []
fake.add_provider(skill_provider)
for i in range(records):
first_name = fake.first_name()
last_name = fake.last_name()
employee.append({
"First Name": first_name,
"Last Name": last_name,
"Birth Date" : fake.date(pattern="%Y-%m-%d", end_datetime=datetime.date(1995, 1,1)),
"Email": str.lower(f"{first_name}.{last_name}@fake_domain-2.com"),
"Hobby": fake.word(),
"Experience" : random.randint(0,15),
"Start Year": fake.year(),
"Salary": random.randrange(75000,150000, 5000),
"City" : fake.city(),
"Nationality" : fake.country(),
"Skill": fake.skills()
})
return employee
df = pd.DataFrame(fake_data_generation(50))
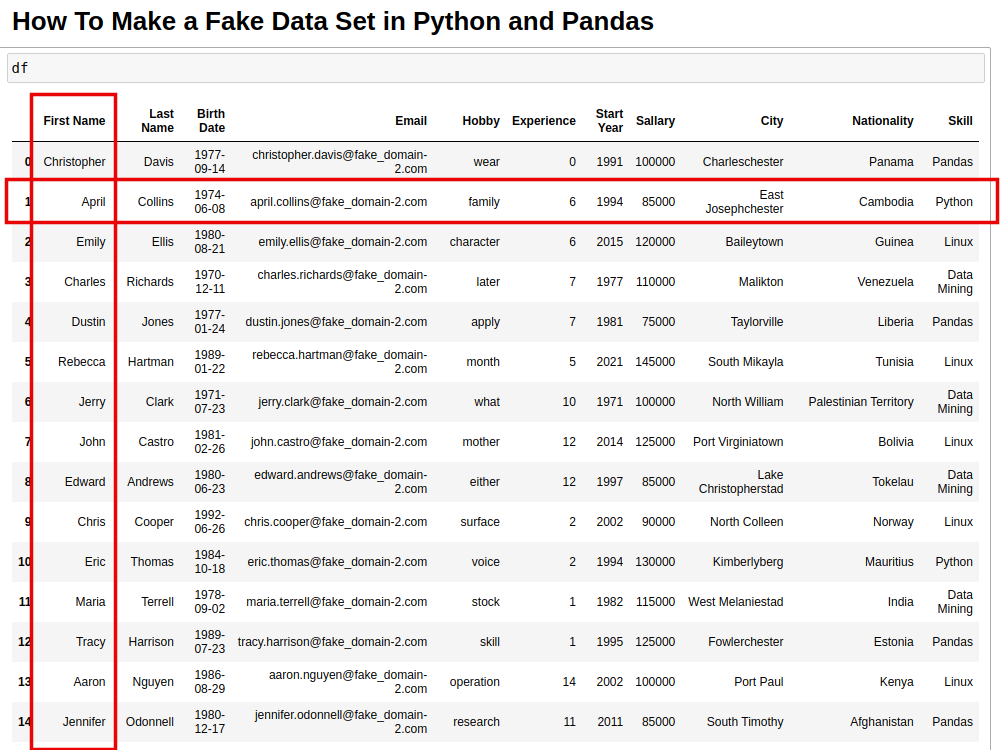
result(output is transposed for redness purpose):
| 0 | 1 | |
|---|---|---|
| First Name | Christopher | April |
| Last Name | Davis | Collins |
| Birth Date | 1977-09-14 | 1974-06-08 |
| christopher.davis@fake_domain-2.com | april.collins@fake_domain-2.com | |
| Hobby | wear | family |
| Experience | 0 | 6 |
| Start Year | 1991 | 1994 |
| Salary | 100000 | 85000 |
| City | Charleschester | East Josephchester |
| Nationality | Panama | Cambodia |
| Skill | Pandas | Python |
Now the DataFrame can be easily exported to CSV - to_csv etc.
The final result is visible on the image below:
6. Create big CSV file with Fake Data
As a bonus we can see how to** generate huge data sets with fake data**. This time we are going to write directly to a CSV file for performance sake:
import csv
from faker import Faker
import datetime
import random
from faker.providers import DynamicProvider
skill_provider = DynamicProvider(
provider_name="skills",
elements=["Python", "Pandas", "Linux", "SQL", "Data Mining"],
)
def fake_data_generation(records, headers):
fake = Faker('en_US')
fake.add_provider(skill_provider)
with open("employee.csv", 'wt') as csvFile:
writer = csv.DictWriter(csvFile, fieldnames=headers)
writer.writeheader()
for i in range(records):
first_name = fake.first_name()
last_name = fake.last_name()
print({
"First Name": first_name,
"Last Name": last_name,
"Birth Date" : fake.date(pattern="%Y-%m-%d", end_datetime=datetime.date(1995, 1,1)),
"Email": str.lower(f"{first_name}.{last_name}@fake_domain-2.com"),
"Hobby": fake.word(),
"Experience" : random.randint(0,15),
"Start Year": fake.year(),
"Salary": random.randrange(75000,150000, 5000),
"City" : fake.city(),
"Nationality" : fake.country(),
"Skill": fake.skills()
})
number_records = 100
fields = ["First Name", "Last Name", "Birth Date", "Email", "Hobby", "Experience",
"Start Year", "Salary", "City", "Nationality", "Skill"]
fake_data_generation(number_records, fields)
The output will be employee.csv in the current working folder. We providing the headers and the number of the records:
number_records = 100
fields = ["First Name", "Last Name", "Birth Date", "Email", "Hobby", "Experience",
"Start Year", "Salary", "City", "Nationality", "Skill"]
7. Conclusion
So, we've taken a look into fake data generation; exploring the basics and its basic use.
We've taken a look at some details like correlated data and quality fake data.
Finally, we saw how to export the saved data to different formats and optimized the process.
The code is available on GitHub.