








1. Overview
In this quick guide, we're going to see how to iterate over rows in Pandas DataFrame.
Pandas offer several different methods for iterating over rows like:
This article will explain the most common ways.
Have in mind that iterating over rows is pretty slow operation and not needed in most cases.
There is even warning on Pandas docs:
Iterating through pandas objects is generally slow.
2. Setup
In the article, we'll use the small DataFrame, which consists of several rows:
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/softhints/Pandas-Tutorials/master/data/csv/extremes.csv')
DataFrame looks like:
| Continent | Highest point | Elevation high | Lowest point | Elevation low |
|---|---|---|---|---|
| Asia | Mount Everest | 8848 | Dead Sea | −427 |
| South America | Aconcagua | 6960 | Laguna del Carbón | −105 |
| North America | Denali | 6198 | Death Valley | −86 |
| Africa | Mount Kilimanjaro | 5895 | Lake Assal | −155 |
| Europe | Mount Elbrus | 5642 | Caspian Sea | −28 |
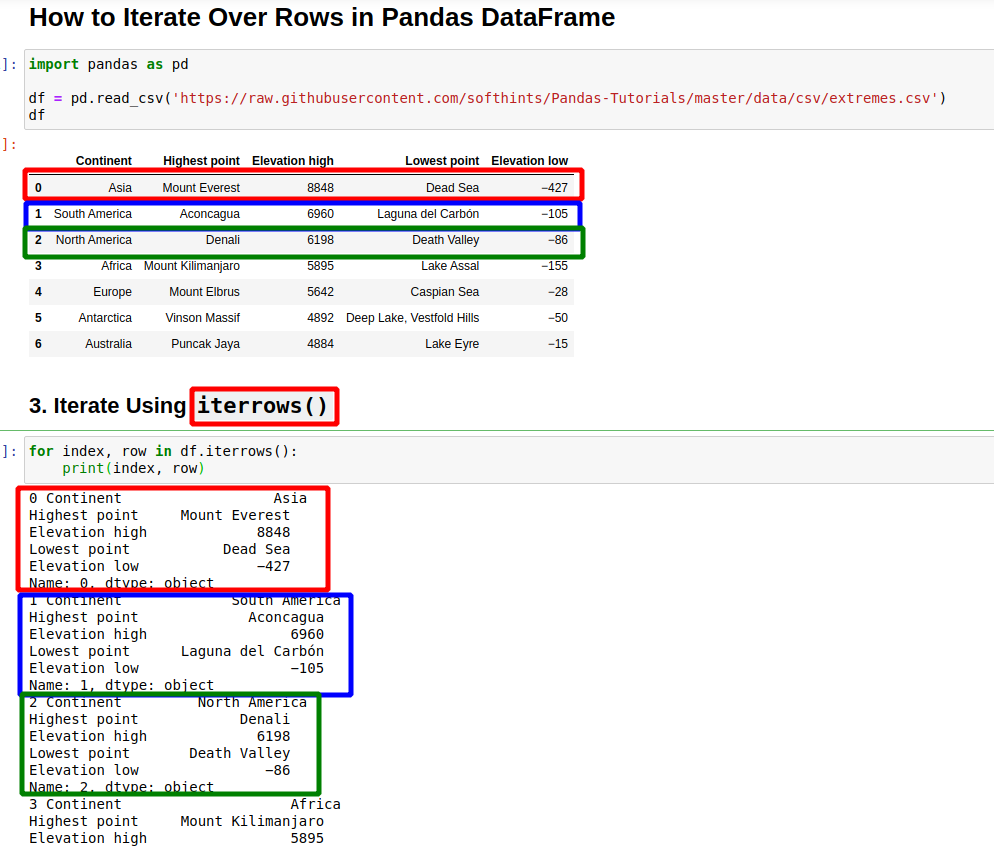
3. Iterate Using iterrows()
Let's start by method iterrows() from the DataFrame class which iterates over rows and returns pairs of (index, Series).
This is the most popular way for iteration in Pandas DataFrame:
for index, row in df.iterrows():
print(index, row)
This will result into index of the first row and all values, then the second etc:
0 Continent Asia
Highest point Mount Everest
Elevation high 8848
Lowest point Dead Sea
Elevation low −427
Name: 0, dtype: object
1 Continent South America
Highest point Aconcagua
Elevation high 6960
Lowest point Laguna del Carbón
Elevation low −105
Name: 1, dtype: object
Row values are accessible with bracket notation: row['Continent']
for index, row in df.iterrows():
print(index, row['Continent'], row['Elevation high'])
The output is:
0 Asia 8848
1 South America 6960
2 North America 6198
3 Africa 5895
4 Europe 5642
5 Antarctica 4892
6 Australia 4884
The image below demonstrates how the method works:
4. Using df.itertuples()
Another method which iterates over rows is: df.itertuples().
df.itertuples is a faster for iteration over rows in Pandas.
To loop over all rows in a DataFrame by itertuples() use the next syntax:
for row in df.itertuples():
print(row)
this will result into(all rows are returned as namedtuples):
Pandas(Index=0, Continent='Asia', _2='Mount Everest', _3=8848, _4='Dead Sea', _5='−427')
Pandas(Index=1, Continent='South America', _2='Aconcagua', _3=6960, _4='Laguna del Carbón', _5='−105')
In order to access only the first row we need to use next(iter( - because generator is returned by this method:
next(iter(df.itertuples(index=True, name='Point')))
output:
Point(Index=0, Continent='Asia', _2='Mount Everest', _3=8848, _4='Dead Sea', _5='−427')
itertuples() have the parameter `name`. If it's missing then the default value is Pandas.
Accessing row data with itertuples() is available by indices - integers or slices:
for row in df.itertuples(index=True, name='Point'):
print(row[3], row[2])
rows are returned as:
8848 Mount Everest
6960 Aconcagua
6198 Denali
namedtuples are subclasses of tuples. You can think of them like something between dict and tuple. It adds more features in comparison to tuples.
Check more for namedtuples: collections.namedtuple
5. Faster Iteration over rows
For bigger datasets a faster solution is required. There are many options available if you need to speed up the loop over rows.
For example you can use frameworks like:
Best for pure Pandas is to use vectorization for your operations.
Another option for processing all rows is list comprehensions. In the example below you can iterate over each row and get values for 2 columns:
[print(x, y) for x, y in zip(df['Continent'], df['Highest point'])]
result:
Asia Mount Everest
South America Aconcagua
North America Denali
or applying some function:
def func(x, y):
return x + ' : ' + y
result = [func(x, y) for x, y in zip(df['Continent'], df['Highest point'])]
result
result:
['Asia : Mount Everest',
'South America : Aconcagua',
...
'Antarctica : Vinson Massif',
'Australia : Puncak Jaya']
6. Conclusion
In this post, we looked at different ways for iterating over rows in Pandas. We focused on basic functionality, but also compared the advantages of different methods.
In general for beginners and medium datasets - df.iterrows() is the way to go. For bigger datasets and more advanced users - itertuples(), list comprehension or custom solution are better.
As usual the code examples are available on GitHub.