








In this short guide, I'll show you how to split a column based on condition in Pandas DataFrame. The example will show how to split a column containing URLs and extract only the last two parts (domain and top-level domain - TLD)
(1) Quick Solution Using . as a Separator
df['domain'] = df['url'].apply(lambda x: '.'.join(x.split('.')[-2:]))
(2) Using rsplit() for a More Efficient Split
df['domain'] = df['url'].str.rsplit('.', n=2).str[-2:].str.join('.')
(3) Using lamdba for conditional split
def find_value_column(row):
if row.url.count('.') == 2:
return row['url'].split('.', 1)[1]
else:
return row['url']
df['domain'] = df.apply(find_value_column, axis=1)
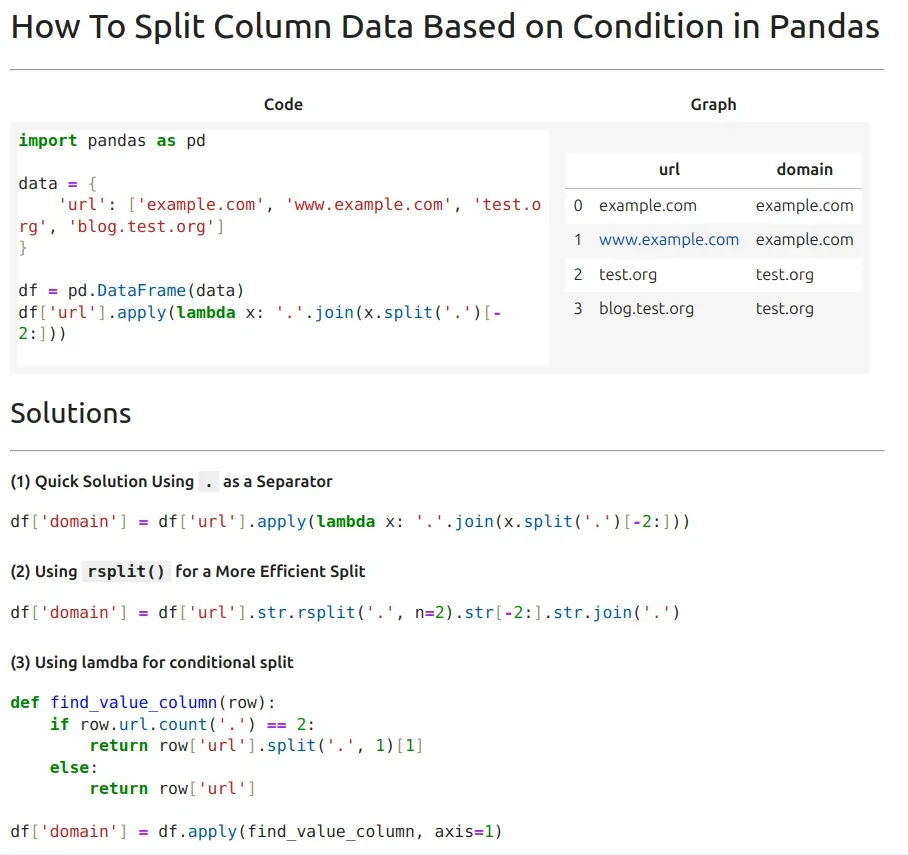
1: Example DataFrame with URLs
Let's create a DataFrame with URLs containing one or two dots:
import pandas as pd
# Sample data
data = {
'url': ['example.com', 'www.example.com', 'test.org', 'blog.test.org']
}
df = pd.DataFrame(data)
Output:
| url | |
|---|---|
| 0 | example.com |
| 1 | www.example.com |
| 2 | test.org |
| 3 | blog.test.org |
2: Extracting the Netloc and Domain
To keep only the last two parts of the domain, we can use split('.') and take the last two elements:
df['domain'] = df['url'].apply(lambda x: '.'.join(x.split('.')[-2:]))
Output:
| url | domain | |
|---|---|---|
| 0 | example.com | example.com |
| 1 | www.example.com | example.com |
| 2 | test.org | test.org |
| 3 | blog.test.org | test.org |
3: Optimized Solution Using rsplit()
A more efficient approach is using rsplit(), which splits from the right and limits the number of splits:
df['domain'] = df['url'].str.rsplit('.', n=2).str[-2:].str.join('.')
This method avoids unnecessary splits and is faster for large datasets.
Conclusion
In this guide, we learned how to:
- Extract the last two parts of a domain name
- Use
split('.')withapply()for flexible extraction - Use
rsplit()for a more optimized approach