








In this article, you can learn how to merge DataFrames in Pandas with handling of missing values.
When working with data in Pandas, you often need to merge multiple DataFrames to consolidate information from different sources. However, not all data align perfectly, and missing values are common. Missing values can cause unexpected results or performance issues.
Create sample data
First let's create two sample DataFrames which can be used to illustrate the merging example:
import pandas as pd
import numpy as np
foo = pd.DataFrame([
['a',1,2],
['b',4,5],
['c',7,8],
[np.NaN,10,11]
], columns=['id','x','y'])
display(foo)
bar = pd.DataFrame([
['a',3],
['c',9],
[np.NaN,12]
], columns=['id','z'])
display(bar)
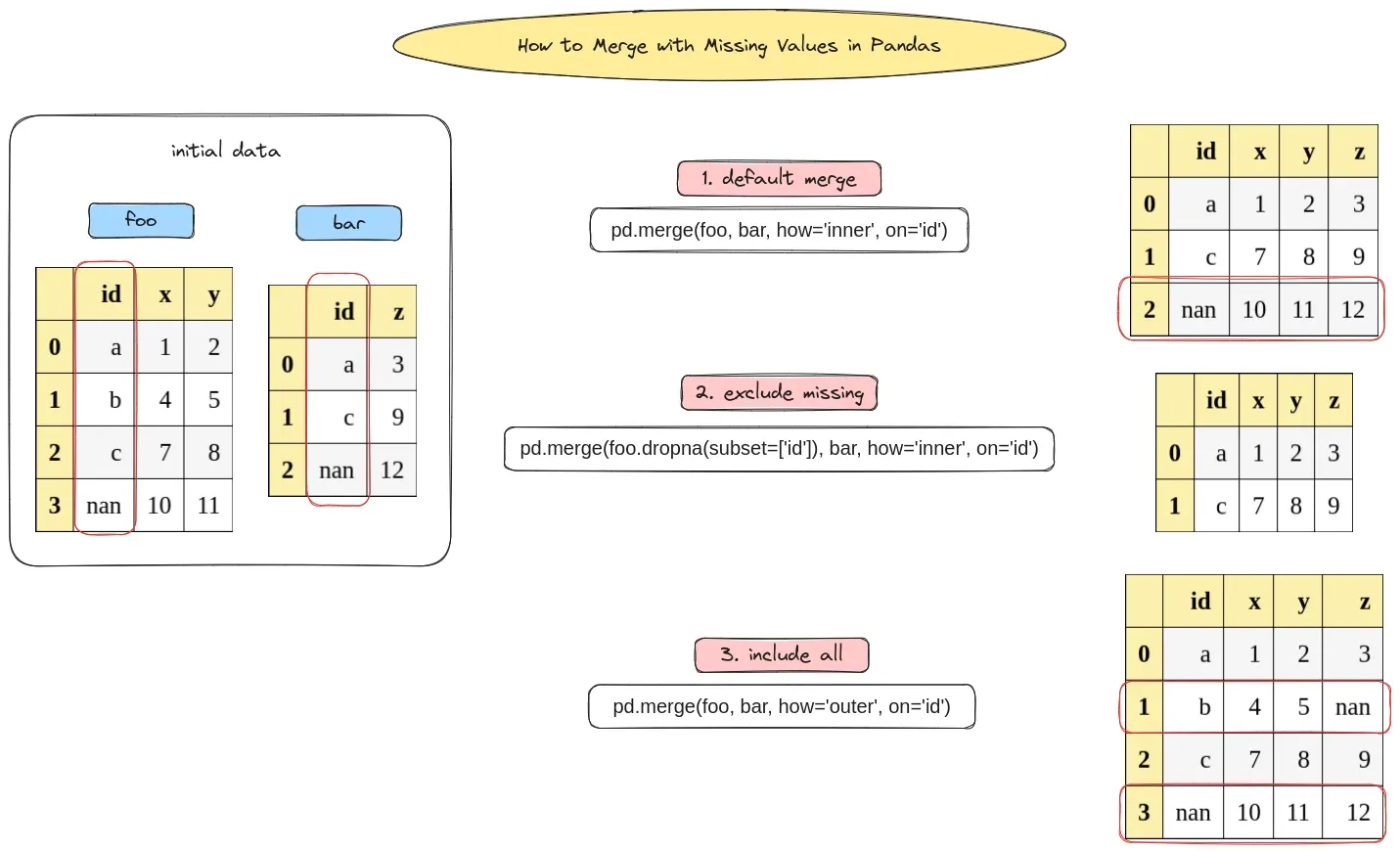
data for foo:
| id | x | y | |
|---|---|---|---|
| 0 | a | 1 | 2 |
| 1 | b | 4 | 5 |
| 2 | c | 7 | 8 |
| 3 | NaN | 10 | 11 |
and bar:
| id | z | |
|---|---|---|
| 0 | a | 3 |
| 1 | c | 9 |
| 2 | NaN | 12 |
merge default bahavior
By default pandas will merge the the missing values from the DataFrames.
pd.merge(foo, bar, how='inner', on='id')
So merging by column id will give us 3 rows instead of 2 ( which differs from the most DB):
| id | x | y | z | |
|---|---|---|---|---|
| 0 | a | 1 | 2 | 3 |
| 1 | c | 7 | 8 | 9 |
| 2 | NaN | 10 | 11 | 12 |
merge without NAN / missing values
To merge without the missing values from the merge column we can drop the values from the first dataframe:
pd.merge(foo.dropna(subset=['id']), bar, how='inner', on='id')
This will give us:
| id | x | y | z | |
|---|---|---|---|---|
| 0 | a | 1 | 2 | 3 |
| 1 | c | 7 | 8 | 9 |
merge with missing values
To keep all values after merging we can use how='outer':
pd.merge(foo.dropna(subset=['id']), bar, how='outer', on='id')
Finally we have data from both dataframes including the missing values:
| id | x | y | z | |
|---|---|---|---|---|
| 0 | a | 1 | 2 | 3.0 |
| 1 | b | 4 | 5 | NaN |
| 2 | c | 7 | 8 | 9.0 |
| 3 | NaN | 10 | 11 | 12.0 |
Conclusion
Merging DataFrames with proper handling of missing values in Pandas is a fundamental operation in data analysis.
By using the merge() function with different join parameters and leveraging Pandas' capabilities to handle missing values, you can efficiently consolidate data from multiple sources.